In today’s edition, the long-awaited release of Quarkus, an AWS Lambda update, as well as JEP and a mailing presenting some little-known Java details.

1. Quarkus 3.0 release
I love Quarkus and the whole philosophy of creating not only the (efficient) framework itself, but also a set of tools to use it effectively. In a world where Spring Boot has (deservedly, AD 2023 it is a great framework too) a dominant position, it’s nice to see a viable competitor that has chosen its niche and is pushing into it (Cloud Native applications, including serverless ones). As I’ve also had quite a bit of experience with the Java EE platform, I still find it hard to believe how much work has been done to rid the standard of its bad reputation, and RedHat has certainly made a contribution. That’s why I’ve been eagerly awaiting Quarkus 3.0, because in addition to the typical changes, in line with the direction the whole ecosystem is going (Jakarta EE 10, MicroProfile 6.0, Hibernate 6.0 and Reactive or the announcement of dropping support for JDK 11) it adds a few own unique flavors.
Let’s start with Dev UI, which shows some of Quarkus’ roots – these kinds of wonders have rather always been the domain of application servers, while on the other hand, it makes you realize how many good ideas existed in such seemingly ancient solutions – enough to mention the panel for changing configuration options or managing extensions. And of course, the Dev UI already appeared with Quarkus 2.0, but now it has been greatly expanded and made more convenient to use. Those with experience with frontend solutions will also quickly recognize the other parent of Dev UI – thanks to the fact that Quarkus can be run in the so-called Dev Mode, such feats as Continuous Testing are available (believe me, it makes a difference). And of course, it’s not that Quarkus is the only one with such capabilities, but it’s the only one of the popular frameworks that treat them as first-class citizens, not as an add-on – and you can feel it.
An extremely interesting change is also the introduction of Mutiny2. Mutiny is a Java library developed by the Quarkus team to simplify the implementation of reactive and asynchronous programming. As Quarkus projects tend to do, it was designed to be an intuitive and simple approach to writing reactive code compared to other libraries such as RxJava and Project Reactor. Mutiny like the projects just mentioned is an implementation of Reactive Streams. For those who may not be familiar, Reactive Streams API is a standard for asynchronous, non-blocking and backpressure-aware processing of data streams in Java, promoting interoperability among reactive programming libraries and frameworks. Around JDK 9, it was one of the most talked about topics in all of JDK, but as the hype for reactive programming has died down somewhat, more implementations have also stopped popping up like mushrooms. That’s why Mutiny has decided to let go of “to abstract” Reactive Streams, and instead simply use the reference version from the JDK – java.util.concurrent.Flow. I guess this is kinda symbolic closure of an era.
What did I miss, though? I was hoping that we would get some broader support for virtual threads, which was mentioned when work on version 3.0 was announced. I did a little code review for myself, and at this point the most interesting bit of VirtualThreads support in remains the extension to resteasy-reactive, which, by the way, has not evolved much since its original publication a year ago on the occasion of JDK 19. It illustrates, by the way, very well how defensive programming support for Loom’s flagship child is today: Just see a slightly simplified example yourself; you can find the original class here:
private boolean isRunOnVirtualThread(MethodInfo info, BlockingDefault defaultValue) {
boolean isRunOnVirtualThread = false;
(...)
Map.Entry<AnnotationTarget, AnnotationInstance> transactional = getInheritableAnnotation(info, TRANSACTIONAL);
if (transactional != null) {
return false;
}
if (runOnVirtualThreadAnnotation != null) {
if (!JDK_SUPPORTS_VIRTUAL_THREADS)
{
throw new DeploymentException((...))
}
if (targetJavaVersion.isJava19OrHigher() == Status.FALSE) {
throw new DeploymentException((...))
}
isRunOnVirtualThread = true;
}
if (defaultValue == BlockingDefault.BLOCKING) {
return false;
} else if (defaultValue == BlockingDefault.RUN_ON_VIRTUAL_THREAD) {
isRunOnVirtualThread = true;
} else if (defaultValue == BlockingDefault.NON_BLOCKING) {
return false;
}
if (isRunOnVirtualThread && !isBlocking(info, defaultValue)) {
throw new DeploymentException((...))
} else if (isRunOnVirtualThread) {
return true;
}
return false
}
Also, if you’ve ever felt bad using nested ifs, I hope seeing the above makes you feel a little better about yourselves.
Sources
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!



2. Amazon is pushing ever wider with its JDK
Okay, so now that we’ve got the latest Quarkus checked, it’s time to look at the bigger picture – last week saw the release of two reports that attempt to describe to us what Java application development looks like in practice – the 2023 State of the Java Ecosystem from New Relic and the 2023 State of Java in the Enterprise Report by Vaadin.
I’ll say up front that the statement ending the previous paragraph is a bit of a stretch here, as both reports were created by specific entities and you can feel it. It’s especially funny in the case of State of Java in the Enterprise. While I suspect that for most of you, my weekly is the only place on the web where you still come across any traces of Vaadin, the Report portrays it as a definitely emerging technology (for example, 34% of respondents use Vaadin Flow “in a significant way”). At least the creators aren’t hiding it – in every possible place, they add a disclaimer that the survey was conducted among Vaadin’s marketing base, which surely distorts a lot of the results.
So, instead of looking at the standard, basically, the same trends – as usual, new Java LTSs are getting more and more adoption, we can also see the steady, continuous adoption of cloud computing (although I think we did the “easy part” as an industry, and quite a few applications that haven’t made it to the cloud world so far will die in the company’s datacenter) – I’ll focus on the most interesting fact from each report.
As for the Vaadin report, it is somehow not very revolutionary in itself. The document talks a lot about application modernization, and by combining the findings from several different charts, one can come to the conclusion that many companies (and mainly in Europe, since by far the majority of respondents are from the Old Continent) are getting more serious about modernization, while the biggest challenge is… UX of the application and the frontend layer in general. Again, the whole thing may be heavily skewed due to the research group (Vaadin has always positioned itself as a FullStack Framework), but you can see that even for in-house applications (64% of respondents create such) a lot of emphasis is placed on this very aspect. It’s a pity that the developers didn’t share Raw Data – I would have loved to see if there was a correlation between e.g. company size and the frontend framework of choice – that’s the kind of cross tabulation I missed the most.
But I’ll admit that I presented this Vaadin to you rather for the sake of completeness. Much more interesting is State of the Java Ecosystem New Relic. Of course, it has most of the shortcomings of its predecessor – New Relic is a service that helps with application telemetry, so document is based on the data collected by their products, so covers only the users. It probably does not reflect the entire ecosystem, as the title would deign to suggest. With this, however, comes an interesting twist – instead of declarative data, collected with the help of a survey, here we are dealing with real production values. So we won’t learn anything about plans and challenges (as was the case with Vaadin), but we can learn a lot of “near machine” details.
Hence, the New Relica report covers mostly technical properties, but that’s probably why you’re checking that newsletter, right? A great deal of space is devoted to, containerization, which is slowly becoming a standard when it comes to the way Java applications are released, and the report contains a lot of interesting details like the amount of CPUs or memory used (TLDR: check your settings for your containers because data shows that a lot of developers have the wrong ones). However, that’s the graph of usage of specific JDK versions that is the most eye-catching. Here the results, especially when compared to 2022, are… interesting:
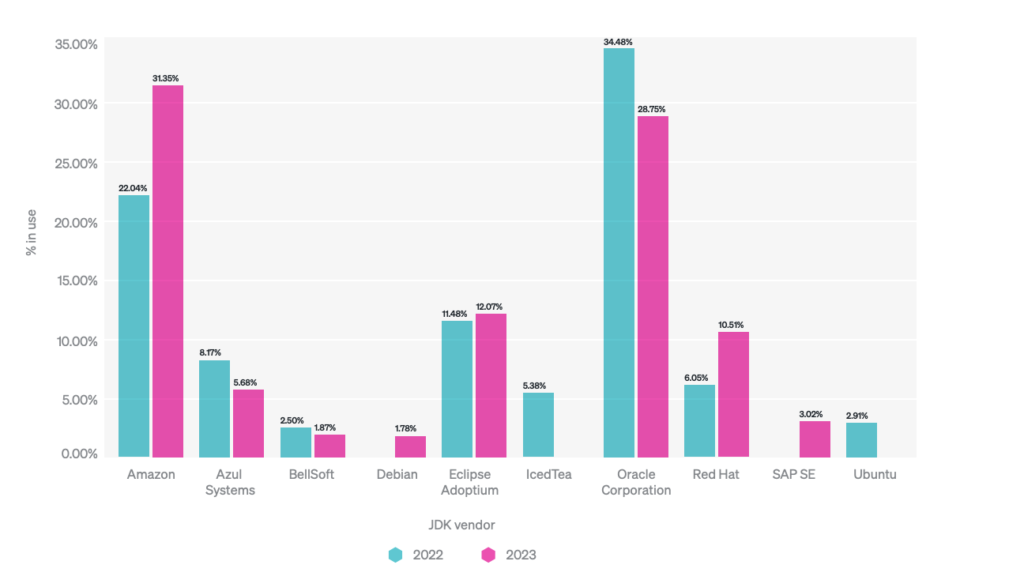
Of course, the results are certainly biased to some extent due to New Relic’s user base, but the trend is clear – more and more people are choosing Amazon’s Corretto as their production JDK. While most JDKs are similar, Corretto is a runtime with additional “twists” – for example, it is additionally optimized to run on ARM (and especially AWS ) processors. It is also the only one to support SnapStart, a method announced last year to reduce Cold Start of Serverless functions. For those who are not familiar with it, due to the amount of nuance, I recommend reading a slightly more extensive study of the topic in one of our previous editions. And while I don’t know too many Corretto use cases outside of AWS, it’s clear that cloud providers’ investments in their own JDKs seem to make sense for them, not least because of their ability to offer additional innovations.
And it’s probable that Corretto will only grow in popularity, as AWS continues to invest in Java support in its cloud. Last week there was a big announcement regarding AWS Lambda – for Amazon’s serverless service is getting support for the latest LTS, JDK 17. As you can easily guess, AWS Lambda is powered by Corretto. “Native” support of the latest LTS also means that you will finally be able to use AWS SnapStart with Java 17.

And if you’re into podcasting, an interesting discussion of Java on Amazon can be found in a recent episode of airhacks.fm by Adam Bien, in which he hosted Maximilian Schellhorn, the Solution Architect working with Java Serverless in AWS itself.
Sources
- State of the Java Ecosystem
- State of Java in the Enterprise
- The road to AWS Lambda SnapStart – guide through the years of JVM “cold start” tinkering – JVM Weekly #24
- AWS Lambda now supports Java 17
- Podcast airhacks.fm: Serverless Java (17) on AWS
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!
3. A peek under-the-hood of Java – Dynamic Agents and “tearing”
A week ago, writing about recently approved JEPs, I promised you that we would return to the topic in the next edition. As promised, let’s now take a look at Prepare To Restrict The Dynamic Loading Of Agents, which was recently published as a JEP Draft. The document proposes changes to the way Java Agents are loaded into an already running JVM to ensure better security – such action will soon end with a warning message. The long-term goal, however, is to prepare the community for future releases of the JDK, which will disable the loading of Agents into a running JVM by default.
Java Agents are components that can live generate & modify an application’s code (while it’s running), used primarily for profiling and monitoring (it’s from their Agent that the New Relica Report from the previous section presented). They were introduced in Java 5, and can be created using the java.lang.instrument API or the JVM Tool Interface. Over the years, JVM instrumentation has been developed min. through the Attach API, introduced in JDK 6, allows tools to just connect to a running JVM. Some tools use the Attach API to load agents dynamically.
In JDK 21, dynamic agent loading will still be allowed, but the mentioned warning will appear. To get it, users must pass -XX:+EnableDynamicAgentLoading on the command line. In future releases, dynamic agent loading will be prohibited by default and will end in an error if attempted without this very option. At the same time, no changes are planned against tools that load agents at VM startup or use the Attach API for purposes other than loading agents or libraries.
And while we’re on the subject of the decision-making process behind specific parts of the language, I couldn’t resist sharing with you On atomicity and tearing, by Brian Goetz. This Java mailing list-sourced opinion statement discusses atomicity, non-atomicity, and so-called ‘tearing’ in the context of Project Valhalla in Java, which aims to enable the flattening of how objects are stored on the heap.
Tearing refers to a situation in which a value is read or written in parts, causing inconsistencies in the read values – the text cites the example of storing a 64-bit number in memory as two 32-bit values. For this reason, in rare cases, race conditions can occur when accessing them. This is a compromise made to ensure good performance for numerical operations at a time when 64-bit variables were not yet efficiently supported by processors.
Now the problem returns in the context of other data types – often much larger than 64-bits – which, in the case of Valhalla, can also be suspectible to “tearing.”
The text presents three choices for Valhalla on how to approach this problem:
- Never allow “burst” values, as in int.
- Always allow “tear” values during race conditions, just as with long.
- Allow to choose programmers explicitely
The safest choice is to never allow tearing, but that would limit the goals of Valhalla. Goetz thus suggests in the text that class authors should make a trade-off between atomicity and efficient flattening of heap objects when designing Value Class, even if this will ultimately cause problems when Race Condition occurs. He argues that the latter should be avoided anyway because their results will never be deterministic by design, and limiting Valhalla to prepare for such edge cases is a bit of a battle with windmills.
What are the lessons in this for you as Java end users? I don’t have many, but knowing how complex the JVM is and how many things need to be taken into account during its evolution builds empathy – especially if you (like me) are one of the laughers who regularly make fun of Valhalla’s constant delays.

Sources
And finally, a little bonus. During coverage of the KotlinConf Keynote (by the way, the promised recordings have appeared), I complained that Kotlin’s mascot was completely forgotten during the event promotion. I was very wrong – not only the cutie is back, but the mascot has also been given a name – from now on it’s called Kodee!
Kodee design underwent a slight facelift, and it also got new colors in line with Kotlin’s own branding, but it remained one of my favorite industry mascots. It also lost none of his expressiveness, but gained a lot of new “reactions”. See for yourself, by the way:

Hopefully, it will only become more and more visible in Kotlin official communication.
Discover more great content!
- Save time and effort
- Read handpicked articles
- Free yourself from spam

