I miało być już regularnie – ale zapomniałem sobie o Wszystkich Świętych, a poprzednią edycje „zakopał” brak ciekawszych informacji. Na szczęście dzisiaj znowu mam dla Was sporo ciekawego.

1. Bo dawno nie było JEP-ów… no to nowe JEPy!
JEP draft: Ahead of Time Compilation for the Java Virtual Machine
No i mamy pierwsze odpryski projektu Leyden, pomimo, że sam JEP nie jest do niego na razie przypięty – choć może to po prostu jeszcze kwestia pozostawania w Drafcie. Mimo wszystko, jest na tyle interesujący, że postanawiam o nim wspomnieć już na tak wczesnym etapie.
JEP draft: Ahead of Time Compilation for the Java Virtual Machine rozwijać ma JVM o możliwość wczytywania aplikacji i bibliotek, które zostały skompilowane do natywnego kodu Ahead of Time. Cel jest jak zawsze ostatnio – przyspieszenie start aplikacji i startową wydajność wykonania. Twórcy chcą przeciwdziałać problemom z wydajnością, wynikającym z obecnego dynamicznego modelu wykonania w trzech etapach: wstępnego interpretowania (Tier 0), kompilacji C1 (Tier 3), a następnie C2 (Tier 4), gdzie etapy 1 i 2 dotyczą specjalnych przypadków kompilacji C1. Całą operacje można by robić od razu kompilatorem C2, ale realnie powodowałoby to długi „rozruch” optymalizowanej wersji. Dobrym przykładem jest kompilator Graal, który przed Java 17 był dostępnym zamiennikiem dla C2, ale jego uruchomienie negatywnie wpływało na aplikację, ponieważ on sam musiał zostać skompilowany przed rozpoczęciem efektywnej pracy. Ponadto proces deoptymalizacji, który ma miejsce, gdy skompilowany przez C2 kod trafia na błędne założenie optymalizacyjne, jest kosztowny, ponieważ wariant profilujący C1 musi zostać ponownie skompilowany, a następnie odrzucony po ponownej kompilacji przez C2.
Sam draft jest bardzo WIP (nie posiada nawet pełnego opisu), ale będę monitorował temat i na pewno do niego wrócimy.
JEP 461: Stream Gatherers (Preview)
Co się stanie kiedy były Tech Lead Akki, Viktor Klang, zaproponuje zmiany w Stream API? Wygląda na to, że dostajemy bardzo przemyślaną propozycje kierunku, w którym chyba najlepiej zaadoptowana w ostatniej dekadzie nowość w języku może być rozwijana.
Chociaż istniejący interfejs Stream API oferuje już bogaty zestaw operacji procesujących (jak .map, .filter ), istniała potrzeba rozszerzenia go i takie jak fixedWindow(2) czy scan((sum, next) -> sum + next). Propozycja Viktora wynika z powtarzających się próśb o dodanie takich dodatkowych operacji do Stream API w Javie 8, których nie można było spełnić, ponieważ ich użycie było zbyt wąskie, aby umieścić je w podstawowym Stream API. Na ten moment nie istnieje jednak opcja, żeby ktoś samodzielnie stworzył sobie własną operacje procesującą, jak to ma miejsce w przypadku interfejsu Stream::collect, w związku z czym czasem okazuje się, że osiągnięcie niektórych efektów jest zaskakująco trudne.

Nowy interfejs Stream::gather służyć ma do tworzenia własnych operacja pośrednich, zdolna do obsługi wielu ich rodzaju. Viktor przeprowadził bowiem w swoim dokumencie Gathering the streams wnikliwą klasyfikacje różnego rodzaju przypadków użycia nowego API, opisujących różne rodzaje operacji strumieniowych, takich jak operacje pośrednie, operacje przyrostowe, operacje stanowe, bezstanowe… całość naprawdę dobrze opisuje wspomniany już oryginalny dokument. Gatherer, bo tak nazwany został nowy interfejs, w swojej budowie bardzo przypomina dobrze znanego Collectora, na którym zresztą został oparty. Żeby Wam to lepiej zwizualizować, przykładem gatherera jest np. metoda fold.
Najważniejsze metody nowego interfejsu to:
/** @param <T> the element type
* @param <A> the (mutable) intermediate accumulation type
* @param <R> the (probably immutable) final accumulation type
*/
interface Gatherer<T,A,R> {
Supplier<A> initializer();
Gatherer.Integrator<A,T,R> integrator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
(...)
}Gatherer został zaprojektowany, aby zapewnić możliwość kompozycji i reużywalności poszczególnych stworzonych z jego pomocą komponentów. Jako przykład może posłużyć implementacja znanego map na wspólnej abstrakcji:
public static <T, R> Gatherer<T, ?, R> map(Function<? super T, ? extends R> mapper) {
return Gatherer.of(
(unused, element, downstream) -> // integrator
downstream.push(mapper.apply(element))
);
}
Jeśli jesteście zainteresowani, bardzo dobre wprowadzenie wideo jak zwykle trafiło na kanał Inside Java.
JEP 462: Structured Concurrency (Second Preview)
Tutaj mamy powtórkę z rozrywki – Strukturalna współbieżność została zaproponowana w JEP 428 i dostarczona w JDK 19 jako API inkubacyjne. Funkcjonalność przeszła (z minimalnymi usprawnieniami pochodzącymi z wprowadzeniem Scope Values) „drugą rundę” w inkubatorze w JDK 20 jako JEP 437. W JDK 21 trafiła zaś do fazy Preview. JDK 22 i JEP 462 nie wprowadzi zaś żadnych zmian, samo API pozostanie jednak w Preview – społeczność uczy się dopiero używania Virtual Threads, potencjalnie więc nie warto spieszyć się ze zbyt szybką stabilizacją dodatkowych struktur kontrolnych dla nich.
JEP 463: Implicitly Declared Classes and Instance Main Methods (Second Preview)
JEP 463 wprowadza drugą wersję koncepcji zaproponowanej w JEP 445, której celem jest uproszczenie procesu pisania „hello world” przez nowych programistów Java i ma na pchnąć Javę w kierunku, by początkujący mogli zaczynać od prostych programów z pojedynczą klasą, bez konieczności rozumienia od takiego samego początku bardziej skomplikowanych funkcji przeznaczonych dla większych projektów. Możliwe ma więc zostać uproszczone deklarowanie programów, co pozwali uczniom na naturalny postęp do bardziej zaawansowanych aspektów Javy w miarę rozwijania ich umiejętności.
Tym razem jednak zmian jest całkiem sporo. Pierwotna idea klas bez nazwy zostały zrewidowane. Zamiast dodawać wsparcie dla klas bez nazwy, jeśli nie zdefiniujemy klasy w sposób jawny, ta otrzyma nazwę wybraną przez system i będzie funkcjonować jako normalna klasa najwyższego poziomu.

Poprzednia wersja wprowadzała też bardzo skomplikowany zestaw reguł wobec metod, które kwalifikowały się jako main takiej klasy bez nazwy. Teraz wybór metody domyślnie wykonywanej została uproszczona do dwuetapowego procesu, który koncentruje się na tym, czy kandydująca metoda main ma parametr String[], bez żadnej niejednoznaczności wynikającej z ograniczenia, że klasa nie może deklarować zarówno statycznej, jak i instancyjnej metody o tej samej nazwie i parametrach, które znajdowały się w oryginalnej propozycji.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Duże nowości w ekosystemie Kotlina – K2 w Becie oraz stabilny Multiplatform
Zawsze twierdziłem, że wersje 1.x.20 w Kotlinie bywają ciekawsze od tych stabilnych. Najnowsza aktualizacja, Kotlin w wersji 1.9.20 to potwierdza, wprowadzając znaczący postęp w obu najważniejszych projektach języka – kompilator K2 wszedł do fazy Beta dla wszystkich platform, a Kotlin Multiplatform osiągnął status stabilny. Rozłóżmy sobie więc to wydanie na czynniki pierwsze.
Beta kompilatora K2 obejmuje platformy JVM, Native, JS i Wasm, ukazując gotowość do szerszych testów. Patrząc w przyszłość, kolejny znaczący kamień milowy dla Kotlina to wersja 2.0.0, która będzie zawierać kompilator K2 już jako w pełni stabilny. JetBrains już teraz zapowiedziało zwiększoną ilość wydań testowych wydań prowadzących do Kotlin 2.0, w tym kilka wersji Beta i Release Candidates (RC), aby szybko rozwiązywać wszelkie problemy. Na ten moment celem jest zapewnienie kompatybilności binarnej i uniknięcie „zatruwania” binarnych plików skompilowanych K2 (sytuacji, gdy skompilowany kod z jednej wersji kompilatora wprowadza problemy, gdy jest używany z binarkami skompilowanymi przez inną wersję), co umożliwi użycie pochodzących z niego artefaktów również w środowiskach produkcyjnych. JetBrains deklaruje, że intensywnie testował kompilator, a użytkownicy są zachęcani do udziału w jego dalszej stabilizacji, testując kompilator K2 w swoich projektach.

Dodatkowo, wśród ważniejszych punktów tej aktualizacji znajdują się choćby znacznie lepsze wsparcie projektów wieloplatformowych, domyślny niestandardowy alokator pamięci w Kotlin/Native oraz usprawnienia wydajności garbage collector’a w Kotlin/Native. Dodatkowo, Kotlin/Wasm wprowadził nowe cele i wsparcie dla najnowszego Wasm GC oraz wsparcie dla API WASI w swojej standardowej bibliotece.
Ale jak pisałem, to nie wszystko. Ogłoszono bowiem, że Kotlin Multiplatform jest już stabilny i gotowy do użycia produkcyjnego. Dla przypomnienia: choć technologia ta umożliwia deweloperom współdzielenie kodu między różnymi platformami, to jednak szczególnie skupia się na programistach mobilnych. Kotlin Multiplatform (KMP) zaciera granice między rozwojem cross-platformowym a natywnym, umożliwiając deweloperom swobodę w zakresie ilości współdzielonego kodu i integrację z każdym projektem – Android, iOS, ale też serwer (choć tu ilość synergii jest mniejsza).
Trakcja jest, co mocno widać po tym, jak ekosystem Kotlin Multiplatform rośnie:
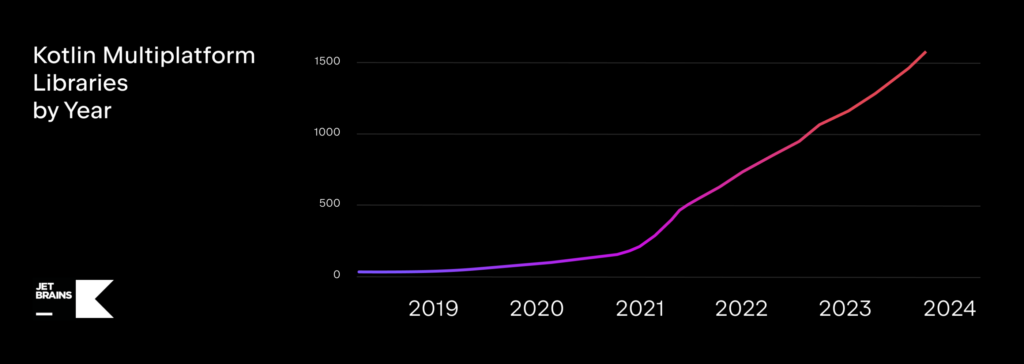
Google ostatnimi czasy wspiera użytkowników KMP coraz to nowymi, eksperymentalnymi wersjami bibliotek Jetpack. Warto tu wspomnieć o nowej wersji Compose Multiplatform 1.5.10, która zgodna jest teraz stabilnym Kotlinem 1.9.20 dającą możliwość pełnego współdzielenia logiki i komponentów interfejsu użytkownika – w tej chwili jest już stabilna dla Androida i desktopu (JVM), z Alfa wsparciem dla iOS i eksperymentalnym dla web (Wasm). Aktualizacja ta wprowadza udoskonalone komponenty Material 3 dla wspólnego kodu, poprawki w polach tekstowych dla iOS, natywną fizykę przewijania z efektem „rubber band”, interoperacyjność z UIKit za pomocą animacji crossfade oraz zwiększoną szybkość kompilacji dzięki wsparciu dla cachowania kompilatora. Dodatkowo, wprowadzono wstępne wsparcie dla kompilatora K2, a także polepszono wydajność renderowania na iOS.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
3. Play Framework odradza się jak Fenix z popiołów
Mieliśmy niedawno Halloween, więc tego typu obwieszczenia nie powinny nas dziwić – martwy wraca z grobu. I tak, wiem, że już mieliśmy chwilę temu dostęp do wersji preview, ale przyznam, że jest to dla mnie jeden z najbardziej zaskakujących powrotów tego roku. Wciąż przecieram oczy. Kiedy wchodziłem w branżę, Play był jednym z głównych kontenerów do tytułu „główny konkurent Springa”, i sam pisałem w nim nawet kilka serwisów produkcyjnych. Tylko wiecie, jak wtedy rzucałem się na wszystko, łącznie z rzucaniem się na kombinacje Groovy/Clojure i Java EE…

Młodość musi się wyszaleć.
Niestety, w pewnym momencie twórcy rozwiązania – wtedy jeszcze Typesafe, dziś znany jako Lightbend – powoli przestawali mieć zainteresowanie tym rozwiązaniem, najpierw przerzucając je na Lagoma (pamięta ktoś jeszcze to rozwiązanie?), a potem na Akkę Serverless. Play w końcu w 2021 roku został oddany społeczności, a pieczę nad nim przejęli nad nim Matthias Kurz i Greg Methvin. I teraz, jak feniks z popiołów, po prawie 4 latach, pojawiły się równocześnie wydanie 2.9 i 3.0. Dlaczego aż dwa? Za tym też stoi ciekawa historia.
Play 3.0 przynosi kluczową aktualizację w rozwoju platformy – migracji z Akki do Apache Pekko – fork Akka 2.6.x, który zdążył już przejść pewną ewolucję i wprowadzić kilka własnych pomysłów. Play 3.0 korzysta z Pekko i jego komponentów HTTP, co sygnalizuje dalszy kierunek modernizacji infrastruktury frameworka. Jednakże dla aplikacji mocno zintegrowanych z Akką, zmiana ta może wymagać pewnych wysiłków migracyjnych. Aby wspomóc użytkowników w tym procesie, zespół Pekko udostępnił szczegółowy przewodnik migracyjny, który nakreśla potencjalne wyzwania. Wydano też Play 2.9, który kontynuuje wykorzystanie Akka i Akka HTTP (i tu rozwiązuje się zagadka, dlaczego pojawiły się dwa wydania na raz).
Impuls do tego technologicznego zwrotu był w dużej mierze napędzany nie samą technologią, a kontrowersjami związanymi z licencją, które pojawiły się po decyzji Lightbend o zmianie takowej dla Akki. Pod poprzednią licencją, Apache 2.0, Akka była swobodnie modyfikowalna i używalna. Natomiast zrewidowana licencja Lightbend wprowadziła komercyjną licencję dla niektórych funkcji Akka, przenosząc kod źródłowy na Business Source License (BSL) 1.1. Sytuacja jest bliźniacza w stosunku do Terraforma, który również zdecydował się na BSL.
Zmiana w licencjonowaniu wywołała silną reakcję, szczególnie wśród tych, którzy zbudowali swoje aplikacje Play w oparciu o pełen zestaw funkcji Akki. Ci programiści stanęli przed wyborem: musieli albo przebudować swoje aplikacje tak, aby pasowały do ograniczeń wersji Akki dostępnej jako open source, nabyć komercyjną licencję na pełen zestaw funkcji lub poszukać alternatywnych rozwiązań.
Jeśli jesteście ciekawi detali, Play wystosował oficjalne stanowisko dotyczące zmiany licencji przez Akkę, które znajdziecie tutaj How Play Deals with Akka’s License Change.
Wróćmy jednak do samych nowych premier. Wydania Play 2.9.0 i Play 3.0 są szczególnie godne uwagi, ponieważ stanowią zwieńczenie niemal czteroletniego rozwoju kierowanego przez społeczność od momentu, gdy Lightbend Inc. przekazał projekt w ręce społeczności. Aktualizacje koncentrują się na wsparciu dla zaktualizowanych języków programowania. Nowy Play (Play’e?) wprowadza kompatybilność z Scala 3, ale tylko dla wersji 3.3.1 i nowszych, zwracając uwagę na potrzebę kroków migracyjnych przy jednoczesnym utrzymaniu wsparcia dla Scala 2.13. Porzucone zostało też wsparcie dla Javy 8, i do działania wymagana jest w tej chwili minimum Java 11.
Ponadto, Play kończy wsparcie dla przestarzałych wersji, takich jak Scala 2.12, sbt 0.13 i Java 8, dostosowując się do swoich zależności, które już nie obsługują tych edycji. Wśród znaczących aktualizacji bibliotek znalazły się Akka HTTP 10.2, aktualizacja do Guice 6.0.0 i Jackson 2.14. Play udoskonalił swoje modułowe komponenty, takie jak sbt-web i sbt-js-engine, i przeszedł na Jakarta Persistence API, aby dostosować się do zaktualizowanych wersji Hibernate i EclipseLink. Wprowadzono także trochę nowe funkcjonalności związanych z działaniem samego frameworków. Pełne release notes znajdziecie tutaj.
Czy moim zdaniem w jest jeszcze na rynku miejsce dla Play Framework? Są we mnie dwa wilki. Z jednej strony, istnieje masa projektów, które w dalszym ciągu go używają (co udowodnić może choćby aktywna społeczność na OpenCollective). W środowisku Scalowym też nie pojawiła się chyba jakaś znacząca konkurencja (Lagom też zdążył w międzyczasie umrzeć), a nawet jeśli, to pamięć o Play wydaje się być tam bardzo silna. Cztery lata to jednak długo – w świecie Javy pojawiła się cała generacja rozwiązań, takich jak Micronaut czy Quarkus, które skutecznie zagarnęły rynek osób zainteresowanych alternatywą dla Springa. Podejrzewam więc, że jeżeli będzie dalej aktywnie rozwijany, to Play raczej okopie się w świecie Scalowym. Trzymam jednak za niego kciuki – mam z nim wiele dobrych wspomnień.

Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


