Dwa tygodnie temu mieliśmy Spring Framework 6.1.0, w dniu dzisiejszym zaś na produkcje trafił Spring Boot 3.2.0, dlatego calutką nową edycje poświęcimy na nowości w ekosystemie Springa – bo tych jest całkiem sporo, a niektóre z nich są szczególne istotne.

Spring bowiem postanowił bowiem dogonić resztę ekosystemu i wprowadził wsparcie dla dwóch bardzo istotnych nowości z punktu widzenia wysokowydajnych aplikacji: Wirtualnych Wątków oraz Projektu CRAC.
Virtual Threads
Dobra, jako że pewnie na ten tekst trafią ludzie, którzy programują w Springu, więc z założenia mogli jeszcze nie zapoznać się jeszcze z konceptem Wirtualnych Wątków (bo takowych w ekosystemie za bardzo jeszcze nie było), bardzo krótkie wprowadzenie do tematu.
Wirtualne Wątki, wprowadzone w JDK 21 w ramach Projektu Loom, mieszają w podejściu Javy do współbieżności. W przeciwieństwie do tradycyjnych wątków, które są bezpośrednio zarządzane przez system operacyjny i są stosunkowo ciężkie (gdzie to słowo rozumiem tutaj jako „generyczne”, wątki wirtualne są lekkie i zarządzane przez JVM. Pozwala to na tworzenie dużej liczby wątków bez narzutu, które zwykle wiąże się z tradycyjnymi wątkami. Virtual Thready są szczególnie korzystne w aplikacjach intensywnie korzystających z I/O, umożliwiając im obsługę współbieżności przy zmniejszonym zużyciu pamięci, szczególnie w scenariuszach związanych z operacjami blokującymi. Oczywiście to tylko wierzchołek góry lodowej, więc jeśli chcecie o Wirtualnych Wątkach dowiedzieć się więcej, idealnym miejscem będzie, jak sama nazwa wskazuje, The Ultimate Guide to Java Virtual Threads, gdzie zamiast jednego akapitu jak tutaj macie po prostu godzinę+ czytania. Bo z wirtualnymi wątkami jest jednak jak z tą legendarną sową – założenia są proste, interesująco robi się gdy trafiamy na szczegóły.

Spring eksperymentował z tymi wątkami już dawno, kiedy znanymi jako Fibers (kurcze, stary jestem, jeszcze w 2018 miałem o nich talka). Zamiast jednak rzucić się na całość jak sroka na błyskotki, podejście Springa obejmuje bardziej ewolucyjną rewizję modeli współbieżności w frameworku, tak aby wykorzystać wirtualne wątki bez wywracania API do góry nogami.
Wsparcie w Springu jest więc warunkowe i zależy od dwóch czynników: uruchomienia aplikacji z użyciem JDK 21 oraz włączenia opcji konfiguracyjnej spring.threads.virtual.enabled. Wtedy to zarówno serwery Tomcat, jak i Jetty w Spring Boot używają wątków wirtualnych do przetwarzania zapytań. Oznacza to, że kod aplikacji, jak choćby metody kontrolerów obsługujące requesty sieciowe, będzie działał na wątkach wirtualnych, oferując potencjalne lepszą w wydajności aplikacji (aczkolwiek osobiście sugeruje sprawdzić to bardziej empirycznie, każda aplikacja może mieć nieco inne bootlenecki).
To jednak nie koniec: integracja wątków wirtualnych w Spring obejmuje też trochę dodatkowych atrakcji. Powstał dedykowany a dedicated VirtualThreadTaskExecutor, a gdy wątki wirtualne są włączone, zarówno SimpleAsyncTaskExecutor jak i SimpleAsyncTaskScheduler skonfigurowane zostają domyślnie do ich użycia. Afektuje to sporo zachowań Springa, w tym metod użycia metod @EnableAsync, asynchronicznego przetwarzania żądań w Spring MVC oraz wsparcia dla blokującego wykonania w Spring WebFlux. Wpływa to też na działanie poszczególnych integracji, takich jak listenery dla RabbitMQ czy Kafki, Spring Data Redis oraz Apache Pulsar (o którym za chwilę). Przyznam, że z mojej strony brakuje mi trochę większej granularności i możliwości wyboru, w których miejscach realnie chcemy Wirtualnych Wątków używać – ułatwiłoby to z pewnością migracje większych projektów. Cóż, może w kolejnych edycjach.
Sam Spring na razie nie opublikował konkretniejszych analiz wpływu Virtual Threadów na aplikacje webowe, ale jako że konkurencja już ten temat rozgrzebywała polecam świetną serię od Quarkusa – implikacje i dobre praktyki powinny być zbliżone.

Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



Project CRAC
Zanim będzie o drugiej ważnej nowości, projekcie CRaC, najpierw muszę wspomnieć o tym czym jest tak zwany problem Zimnego Startu.
Jak pewnie wiecie, że aplikacje napisane w Javie – zanim jeszcze będą w stanie „przyjmować” ruch – zwykle potrzebują trochę czasu na rozruch. Cechuje to zarówno klasyczne aplikacje serwerowe (które do osiągnięcia pełnej wydajności wymagają procesu kompilacji JiT, odpalanej na bazie dynamicznej charakterystyki ruchu), jak i aplikacji Serverless (które po prostu w sytuacjach brzegowych wymagają całej maszynerii pod spodem).

Na szczęście, istnieje kilka rozwiązań które ten „zimny start” nam zredukują – taki GraalVM pozwala nam na tworzenie „natywnych” wersji aplikacji Java, ale istnieją też metody jak Fast Startup czy AppCDS służyły do cache’owania poszczególnych fragmentów runtime JVM-a, aby nie trzeba było ich inicjować od zera przy starcie. Co jednak, jeśli moglibyśmy za każdym razem odczytywać rozgrzany, odłożony na później kod aplikacji, a może i kompletną pamięć już z wczytanymi danymi, choćby dla modeli ML? By to osiągnąć, na naszym radarze powinno pojawić się mechanizm, CRIU.
Checkpoint/Restore in Userspace (CRIU) to funkcja Linuxa, która umożliwia wykonanie „zrzutu” na dysk całego działającego procesu aplikacji. Następnie, kolejna instancja może być uruchomiona z tego punktu, w którym wykonano wspomniany zrzut, co skraca czas rozruchu.
Mam wśród czytelników jakichś retro-graczy? Jeśli tak, to całość działa w podobny sposób jak funkcjonalność Save State w emulatorach. Metody takie jak AppCDS przypominają klasyczne zapisywanie – wybieramy te fragmenty, które pozwolą nam później odtworzyć stan aplikacji, i tylko je zapisujemy. Save State nie bawi się w takie finezje – jako, że komputery poszły do przodu i mamy więcej przestrzeni dyskowej, to po prostu zrzucamy cały stan pamięci na dysk (co w wypadku starych konsol może być np. zawrotnym 1Mb) i potem sobie odtwarzamy 1:1 gdy jest to potrzebne.

CRIU posiada swoje problemy – zarówno z punktu widzenia bezpieczeństwa, jak i wygody użytkowania – mówimy tutaj bowiem o generycznej funkcji systemu operacyjnego, znajdującej się poza JVM. Każda aplikacja ma zaś nieco inną charakterystykę i w zależności od tego, czy mówimy o serwerze aplikacyjnym, aplikacji webowej czy batchowym jobie zapis na dysk powinien odbywać się w innym momencie, który może być trudny do wychwycenia bez kontekstu maszyny wirtualnej. Jak pisze OpenLiberty w swoim tekście Faster start-up for Java applications on Open Liberty with CRIU:
It would be useful to have an API so that the application can specify when it would like a snapshot to be taken; this would be a valuable addition to the Java specification.
OpenLiberty od tamtem pory dorobiło się własnego mechanizmu używającego CRIU.
Spring zdecydował się jednak na konkurencyjne rozwiązanie – i to najwyższy czas aby wreszcie przejść do CRaC.
Project CRaC (Checkpoint/Restore in Application Continuation) to tooling umożliwiających użycie mechanizmu checkpoint/restore z aplikacjami Java. Pozwala to na zapisanie stanu działającej JVM (checkpoint) i późniejsze jego przywrócenie, umożliwiając szybsze uruchomienie aplikacji poprzez ominięcie początkowego ładowania i procesów rozgrzewania. Stosunku do „gołego” CRIU wprowadza on odpowiednie hooki i usprawnienia usprawniające użycie całości z JVM.
Tak jak w wypadku Wirtualnych wątków, aby korzystać z Integracja Spring Framework z Project CRaC, muszą być spełnione pewne warunki: JVM z włączoną funkcją checkpoint/restore (obecnie opcja ta jest dostępna tylko na Linuxie, wspiera je choćby Azul czy Liberica, choć tylko ta ostatnia w wersji 21 umożlwiającej równoczesne użycie Wirtualnych Wątków), dołączenie biblioteki org.crac:crac (wersja 1.4.0 lub wyższa) do classpath oraz określenie specyficznych parametrów linii poleceń, takich jak -XX:CRaCCheckpointTo=PATH. Proces checkpoint tworzy pliki, które reprezentują pełny stan pamięci JVM, w tym potencjalnie wrażliwe dane, co wymaga starannego rozważenia implikacji bezpieczeństwa. Całość wpływa też na losowość java.util.Random, który staje się „nieco” mniej losowy, ponieważ wszystkie procesy odpalane są na tym samym seedzie.

Integracja w Springu jest dość bogata, efektywnie bowiem wpina się w naturalny cykl życia aplikacji. Checkpoint można wywołać za pomocą polecenia jcmd application.jar JDK.checkpoint, co skutkuje zatrzymaniem przez Spring wszystkich działających beanów i umożliwieniem im zamknięcia zasobów. Po przywróceniu te same beany są ponownie uruchamiane, otwierając zasoby tam, gdzie to odpowiednie. Poza jednak ręcznym wywołaniem, kluczowa funkcja tej integracji to możliwość konfiguracji automatycznego uruchomienia checkpoint/restore przy starcie aplikacji. Ustawienie właściwości systemu Java -Dspring.context.checkpoint=onRefresh powoduje automatyczne utworzenie checkpointu podczas startu na etapie LifecycleProcessor.onRefresh. W praktyce oznacza to, że wszystkie (nie leniwe) singletony są już zinstancjonowane, wywoływane są też callbacki InitializingBean.afterPropertiesSet, ale nie wystąpiły jeszcze metody Lifecycle.start, a ContextRefreshedEvent nie został jeszcze opublikowany.
Co więcej w nowym wydaniu?
Spring Framework 6.1
Spring Framework 6.1 to na pewno szeroko rozumiana kompatybilność z JDK 21. Nowa wersja wprowadziła też trochę ulepszeń w kontekście samego „kontenera aplikacji”, szczególnie w zakresie funkcji zarządzania cyklem życia. Teraz integruje on w sobie funkcje takie jak możliwość wstrzymania i wznawiania zadań oraz lepszą kontrolę nad zamykaniem zadań w ThreadPoolTaskExecutor i ThreadPoolTaskScheduler. Nowa wersja wprowadza również lepsze observability dla metod @Scheduled i lepsze „fabryki” do tworzenia walidatorów, a także wbudowane wsparcie walidacji metod dla parametrów metod kontrolerów zarówno w Spring MVC, jak i WebFlux. Eliminuje to potrzebę stosowania adnotacji @Validated na poziomie klasy kontrolera. A jak już przy anotacjach jesteśmy, @PropertySource poszerza wsparcie symboli w wyrażeniach SpEL (Spring Expression Language).
Wprowadzenie też RestClient, nowego synchronicznego klienta HTTP podobnego do WebClient, ale prekonfigurowanego i dopasowanego pod zapytania REST-owe. Interesująco wyglądają też zmiany w kontekście dostępu do bazy danych – ciekawym aspektem wydanie jest bowiem wprowadzenie JdbcClient, zunifikowanej fasady dla JDBC. Co więcej, nowych możliwości doczekał się też wsparcie dla R2DBC. Listę zmian dotyczącą warstwy danych zamykają zaś usprawnienia cyklu życia aplikacji jeśli chodzi o transakcyjność.
Listę wszystkich zmian znajdziecie tutaj.
Spring Boot 3.2.0
Poza nowościami z Spring Framework 6.1, Spring Boot 3.2.0 wprowadza też kilka nowych integracji i funkcji. Wśród nich wyróżnia się rozszerzone wsparcie dla Apache Pulsara (którym zajmiemy się już za chwilę). Wsparcie wspomnianych już interfejsu RestClient z Spring Framework 6.1 zapewnia zaś programistom funkcjonalne, blokujące API HTTP. Pojawiło się również wsparcie dla JdbcClient. Ważnym dodatkiem jest automatyczne logowanie Correlation Id podczas korzystania z Micrometera, co pewnie uchroni nie jednego programistę przed przykrą sytuacją braku wystarczającej ilości informacji w wypadku awarii. Wsparcie auto-configuration doczekały się też adnotacji z Micrometera: @Timed, @Counted, @NewSpan, @ContinueSpan i @Observed.
Wersja 3.2.0 ulepsza budowanie obrazów Docker w oparciu o standard Cloud-Native Buildpacks od Cloud Native Foundation, task do budowania Dockerowych obrazów domyślnie zaś używają teraz konfiguracji z hosta.
Ponownie, mniejszych zmian jest znacznie więcej, listę wszystkich znajdziecie tutaj.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
Najciekawsze wydania towarzyszące
Spring dla Apache Pulsar
Apache Pulsar to konkurent Kafki, który został oparty o architekturą, która oddziela przestrzeń do przechowywania danych od mocy obliczeniowej. Umożliwiając to elastyczne skalowanie tych części niezależnie, osiągając różne poziomy izolacji zasobów. Kontrastuje to z monolityczną architekturą Kafki, która ściśle łączy moc obliczeniową z przechowywaniem, wymagając wspólnego skalowania zasobów.
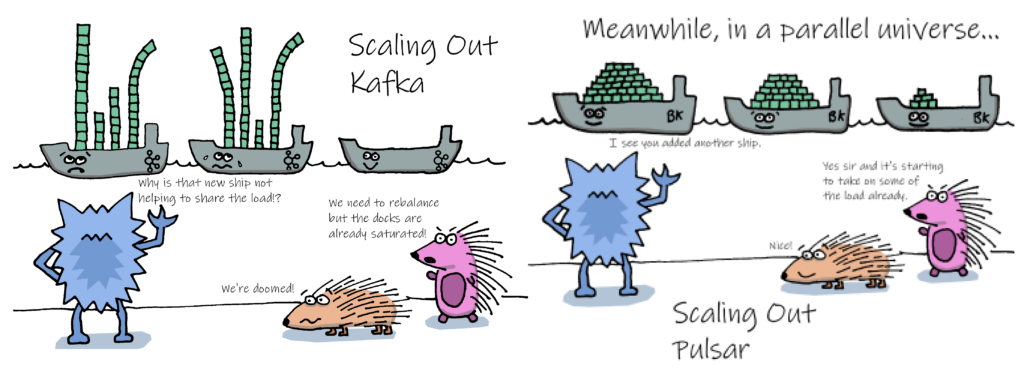
Spring for Apache Pulsar 1.0.0 to integracja ułatwiająca tworzenie aplikacji opartych o Apache Pulsar. Główną zależnością jest moduł spring-pulsar-spring-boot-starter, który upraszcza proces konfiguracji i rozwijania aplikacji. Integracja ta zapewnia automatyczną konfigurację ważnych komponentów, takich jak PulsarClient, który jest wykorzystywany zarówno przez producentów, jak i konsumentów wiadomości. Umożliwia także wygodną produkcję i konsumpcję wiadomości za pomocą PulsarTemplate oraz łatwe subskrybowanie i reagowanie na wiadomości z wykorzystaniem adnotacji @PulsarListener. Dodatkowo, integracja ta oferuje wsparcie dla TLS i różnych mechanizmów autentykacji.
Przy okazji wspomnę też o Spring Integration 6.2. W nim jak zwykle bardzo dużo, ale nic co jakoś odmieniłoby czyjeś życie. Jeśli jednak używacie Kafki, MongoDB czy Debezium – warto zerknąć.
Spring Security 6.2 i Spring Session 3.2.0
Najważniejsze zmiany w Spring Security 6.2 obejmują automatyczne włączanie .cors() w wypadku obecności bean CorsConfigurationSource, a także ułatwienie tworzenia wszelakich konfiguracji: nową metodę AbstractConfiguredSecurityBuilder.with(…), oraz uproszczenie konfiguracji komponentu klienta OAuth2. Ponadto, dodano wsparcie dla wylogowania OIDC Back-channel, usprawnienia propagacji SecurityContext, konfigurowalne RedirectStrategy i parsowanie żądań HTTP Basic..
Z kolei Spring Session 3.2.0 (które w mojej głowie zawsze było bardzo blisko spięte z security) skupia się na dwóch kluczowych ulepszeniach. Pierwszym jest wprowadzenie SessionIdGenerator, umożliwiającego generowanie niestandardowych identyfikatorów sesji. Drugie to znaczące ulepszenie możliwość bezpiecznej deserializacji sesji Redis.
Pojawił się też Spring Authorization Server 1.2, ale w jego wypadku prawie wszystkie zmiany to patchnotes więc trochę 🤷.
Towarzyszących wydań jest więcej, ja skupiłem się na tych z mojej perspektywy najbardziej interesujących. Chyba moim ulubionym sposobem na śledzenie nowych wydań jest Kalendarzu Springowym, który i Wam polecam.

Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


