Dzisiaj znowu wracamy do tematów związanych ze zmianami, które pojawią się w Javie jeszcze w tym roku.

1. Co Alan Bateman opowiedział o przyszłości Wirtualnych Wątków?

Jeśli myślicie, że wraz z JDK 21 zakończyła się historia dynamicznego rozwoju Wirtualnych Wątków, to mam dla Was trochę niespodzianek. Podczas konferencji FOSDEM Alan Bateman, jeden z architektów JDK, przedstawił bowiem postępy w Projekt Loom.
Zamiast jednak skupiać się nad bieżącym stanem, w swoim talku wyszedł on kilka kroków do przodu, prezentując stojące przed projektem wyzwania. Głównym problemem związanym z obecną iteracją Projektu Loom, który Bateman podkreślił, było zagadnienie przypinania (pinning) wątków.
Wraz ze stabilizacją wątków wirtualnych w JDK 21, społeczność generalnie z entuzjazmem przyjęła tę nowość. Konceptualnie ciężko znaleźć przeciwników obecnego designu, a większość sceptyków skupia się na problemie „przypinania”, związanym z metodami synchronizowanymi, sekcjami JNI lub instrukcjami Object.wait. Przypinanie występuje, gdy wirtualny wątek, trzymając monitor/”lock”, próbuje zwolnić miejsce innemu wirualnemu wątkowi, ale nie jest w stanie tego zrobić. Dzieje się tak, ponieważ implementacja monitora w JVM wiąże „carrier thread” (jak Alan opisał to na swojej prezentacji – platformowego giganta noszącego wirtualnych braci na plecach) w taki sposób, że nie może on uwolnić monitora i kontynuować innych zadań. Problem ten, szczególnie widoczny, gdy wątek wirtualny albo parkuje podczas metody synchronizowanej w celu wykonania operacji takich jak I/O socket, lub blokuje się próbując wejść do metody synchronizowanej. Potencjalnie powoduje to degradację wydajności, problemy ze skalowalnością, zakleszczenie, zniszczenie i głód.

Całość jest problemem trudnym do rozwiązania, ponieważ większość wyzwań stanowią przestarzałe z dzisiejszej perspektywy mechanizmy lockowania, istniejące w maszynie wirtualnej od lat. Żeby obsłużyć niektóre warunki brzegowe Wirtualnych Wątków, niezbędna okazała się modernizacja całego mechanizmu lokowania w Javie, co jest procesem żmudnym i będzie trwało zapewne następne parę lat, patrząc na doświadczenia z innych tego typu inicjatyw. W międzyczasie Patricio Chilano Mateo z zespołu Hotspot zaimplementował plan B. Jest to realizowane poprzez „podmianę” identyfikatora właściciela wirtualnego wątku na klasyczny wątku Java (piękny haczur) w locku, co samo w sobie wprowadza narzut (trzeba się do odpowiednich struktur dokopać i rzeczoną wartość podmienić), ale na ten moment wydaje się dość skutecznie rozwiązywać problem pinningu (przynajmniej w niektórych miejscach). Konwersacje na ten temat możecie znaleźć w dwóch wątkach (1, 2) listy mailingowej JDK.
Bateman przedstawił również nowe podejście do zarządzania zapytaniami IO. Do tej pory ten implementowany był jako platform thread, który dopiero przekazywał pracę do wirtualnych wątków, co w zasadzie każdorazowo kończyło się context switchem. Nowe rozwiązanie zakłada, że sam Poller ma być wirtualnym wątkiem, dzięki czemu (w większości przypadków) zapytania będą mogły być wykonywane w tym samym wątku, który je przyjął.
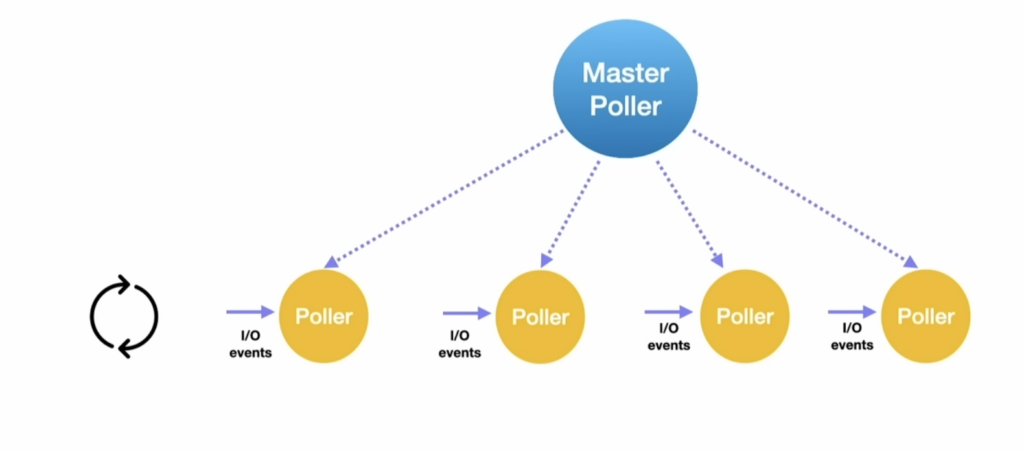
Bateman wspomina, że całość konceptu inspirowana była paperem User-level Threading: Have Your Cake and Eat It Too, w którym naukowcy z Uniwerytetu w Waterloo opisali różne podejścia do strategii I/O. Ten nie jest dostępny publicznie, ale przybliżenie stanowi prezentacja wideo twórców, prawdopodobnie wystarczające dla 99% ludzi, którzy akurat nie implementują poolingu w języku w swoim aktualnym sprincie ;).
Poza tymi konkretnymi ulepszeniami, Bateman poruszył także szersze zmiany w krajobrazie współbieżności, takie jak usprawnienia w poolu Fork-join mające na celu lepsze wykorzystanie zasobów, zwłaszcza w systemach o mniejszej liczbie rdzeni.
A jak już jesteśmy przy wideo, to drugim wartym zapoznania się jest z pewnością Java Language Update – Early 2024 Edition. W nim to Viktor Klang, kolejny Software Architect z Oracle pracujący w Java Platform Group, snuje opowieść o tym, jak pojedyncze, oderwane od siebie w teorii zmiany w Javie mają sens jako całość i kierują język w nowym, bardzo spójnym kierunku. Uważam, że jest to seans obowiązkowy dla każdego, kto chce lepiej zrozumieć jaki obrazek wyłania się z pojedynczych puzzli.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Nowe JEP-y: Elastyczne konstruktory i pochodne rekordy

JEP Draft: Flexible Constructor Bodies (Second Preview)
Ten JEP autorstwa Archie Cobbsa i Gavina Biermana to ewolucja JEP 447: Statements before super(…), który dopiero okaże się w JDK 22, a już zdążył zmienić nazwę i przechodzić będzie pewne zmian… i to takie zaskakująco ciekawe. Na pierwszy rzut oka nie mówimy tutaj o jakichś Proponuje dalsze uelastycznienie składni konstruktorów Javy – o ile pozwala ona bowiem na umieszczanie w konstruktorach instrukcji, które nie odnoszą się do tworzonej instancji, o ile nie będą one odczytywane przed wyraźnym wywołaniem konstruktora. Ciekawa jest motywacja stojąca za tą zmianą – według treści JEPa będzie to wymagane przez Value Classes, które zostaną zaimplementowane jako część Project Valhalla. Na razie nie wiemy za wiele więcej, ale po raz kolejny przeglądając aktualizacje JEP-ów widzimy sugestię, że prawdopodobnie już końcówką roku będziemy mieli okazję zapoznać się z jakimiś pierwszymi publicznie dostępnymi w ramach JDK wersjami projektu.
Poza powyższym, JEP wspomina również nieokreślone jeszcze zmiany w obsłudze klas lokalnych, ale na detale takowych pewnie musimy zaczekać do kolejnej iteracji. Oprócz tego wydaje się, że pozostały design projektu pozostaje bez zmian.
JEP draft: Derived Record Creation (Preview)
Drugi z dzisiejszych JEP-ów dotyczy długo oczekiwanego usprawnienia tego, jak działają Javowe rekordy i zbliżenia ich do odpowiedników w innych nowoczesnych językach programowania.

JEP draft: Derived Record Creation (Preview) wprowadza bowiem koncepcję instancji pochodnych, które mogą być tworzone na bazie istniejących instancji rekordów. Rekordy bowiem, będąc niezmiennymi z założenia, często wymagają tworzenia nowych instancji, aby odzwierciedlić zmiany w danych, co prowadzi do popularnego wzorca tak zwanych wither method:
record Point(int x, int y, int z) {
Point withX(int newX) {
return new Point(newX, y, z);
}
Point withY(int newY) {
return new Point(x, newY, z);
}
Point withZ(int newZ) {
return new Point(x, y, newZ);
}
}
Nowy JEP proponuje składnię, która pozwala programistom na zwięzłe wyrażanie tych modyfikacji w desygnowanym temu bloku kodu, zwiększając wyrazistość języka i redukując powtarzalny kod związany z obsługą immutability.
Przykład warty jest tysiąca słów, więc tak prezentować się będzie użycie:
record Point(int x, int y, int z) { }
var nextLoc = new Point(3,3,3)
Point finalLoc = nextLoc with { x = 0; };
/// finalLoc: Point(0,3,3)
Oczywiście, nigdy nie jest prosto, i tak samo w tym przypadku tworzenie tego typu pochodnych rekordów będzie obwarowane pewnymi regułami i warunkami brzegowymi, po te jednak odsyłam do oryginalnego JEP-a.
Jako, że już wywołałem Kotlina, to warto porównać sobie to podejście do jego rozwiązania podobnego problemu. Kotlin oferuje bowiem tak zwane data classes, które podobnie jak rekordy Javy, są przeznaczone do przechowywania danych. Mają one wbudowaną metodę copy, która pozwala na łatwe tworzenie zmodyfikowanych instancji przez podani. Twórcy Derived Records postawili jednak na większą elastyczność transformat, którą zapewnia zaproponowany przez nich blok with , jak na przykład możliwość operowania na zagnieżdżonych rekordach (przykład z JEPa):
Marker scaled = m with {
loc = loc with {
x *= 2;
y *= 2;
z *= 2;
}
};Oprócz powyższych, opisywane niedawno JEP 465: String Templates oraz JEP 466: Class-File API (Second Preview) otrzymały status kandydata.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
3. Release Radar

Docker Desktop 4.27
Zaskoczeni widząc tu Docker Desktop? A nie powinniście.
Docker Desktop 4.27 wprowadza bowiem natywne wsparcia dla frameworka Testcontainers, którego twórców, AtomicJar, Docker niedawno kupił. Opiera się ono o Enhanced Container Isolation, komercyjną funkcję Docker Desktop zwiększającą bezpieczeństwo kontenerów poprzez dodatkowe mechanizmy izolacji. Chodzi tu głównie o jeszcze mocniejsze ograniczenie sposobów, w jakim złośliwy kod uruchomiony w jednym kontenerze mógłby wpłynąć na hosta systemowego lub inne kontenery. Całość została dość przystępnie (pamiętajcie jednak – dalej mówimy o warstwie OS i choć lekka znajomość Unixa się przyda) opisana w oficjalnej dokumentacji Dockera.
Inną godną uwagi aktualizacją dla programistów Java w Docker Desktop 4.27 jest stabilizacja nowego polecenia docker init. To narzędzie upraszcza początkową konfigurację projektów Dockerowych, automatycznie generując Dockerfile, pliki Compose i .dockerignore, dostosowane do potrzeb projektu. Dopasowuje go do potrzeb projektu, i choć w Javie opcje są na razie dość ograniczone (przykładowo, obecna wersja Dockerfile używa Mavena i Eclipse Temurina i nie da się tego skonfigurować), to i tak generowane plik robią wrażenie, zwłaszcza masa komentarzy i linków w Dockerfile czy wielkość .dockerignore.

Micronaut 4.3
Kluczowe usprawnienia Micronaut Framework 4.3 to ulepszona integrację z Kotlin Symbol Processing (KSP), zawierająca poprawki z najnowszej wersji Kotlin 1.9.20. Wprowadzono też nowe moduły, takie jak Micronaut Chatbots (no bo przecież jak by inaczej) i Micronaut EclipseStore, zapewniający integracje z następcą projektu MicroStream. Ponadto, wydanie usprawnia warunkowe cachowanie i umożliwia konfiguracje wielodziedziczenia przy użyciu języka wyrażeń frameworka.
Oczywiście to nie koniec, bo jak to każde nowe wydanie Micronauta, tak i 4.3 przynosi aktualizacje w całym swoim ekosystemie, w tym moduły integracji z chmurą dla AWS, GCP, Azure i Oracle Cloud, oferując ulepszenia i nowe funkcjonalności, takie jak subskrypcje Push Pub/Sub dla GCP. Zaktualizowano używaną wersję GraalVM Native Image Build, poprawiono wsparcie dla Docker i Java 21, a Bill of Materials (BOM) Micronauta umożliwia teraz łatwiejsze zarządzanie zależnościami poprzez włączenie wersji z różnych modułów. Aktualizacje dostały narzędzi migracji bazy danych wraz z poprawkami różnych modułów, takich jak Micronaut Data, gRPC, Kafka.

Amper 0.2.0
To jeszcze na koniec update do projektu Amper, który (dla przypomnienia, więcej o projekcie znajdziecie tutaj) jest eksperymentalnym narzędziem do deklaratywnej konfiguracji buildów projektów stworzonym przez JetBrains. Otrzymał on właśnie aktualizację do wersji 0.2.0. Pewnie bym o niej nie wspominał – jako że to raczej mały upgrade – ale jest okazją aby opowiedzieć o trochę mniej znanej funkcjonalności Gradle.
Wprowadza ona wsparcie dla Gradle Version Catalogs – funkcjonalności wprowadzona w Gradle 7.0, która pozwala na centralne zarządzanie wersjami bibliotek oraz wtyczek, co ułatwia zarządzanie zależnościami w wielomodułowych projektach. Dzięki temu, zamiast powtarzać wersje bibliotek w różnych modułach, można je zdefiniować raz w katalogu wersji i odwoływać się do nich za pomocą aliasów. Ampera umożliwia teraz dostęp do zależności zadeklarowanych w tych katalogach, używając składni $libs.library.name.
IDE ze wsparciem Ampera (IntelliJ IDEA, Android Studio i JetBrains Fleet) dostały też auto-podpowiadanie dla zależności działające na bazie JetBrains Package Search. Ponadto od wersji IntelliJ IDEA 2024.1, możliwe jest tworzenie nowych projektów Kotlinowych opartych na Amperze bezpośrednio z kreatora nowych projektów.
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


