Wracamy dziś do standardowej edycji – i ta mi się przez to ostro rozrosła. Ale mam nadzieje, że jest fajnie.

1. O czym mówi nam „2024 State of the Java Ecosystem”

Dużo raportów ostatnio. Dopiero co dwa tygodnie temu poświęciłem całą edycję statystykom DataDoga dotyczących poziomu bezpieczeństwa aplikacji Javowych, a w międzyczasie zdążył się ukazać 2024 State of the Java Ecosystem od NewRelica. Jest to chyba pierwsza publikacja tego typu w tym roku (ogarniacie, że już jesteśmy prawie na półmetku 🥶?). Rzućmy sobie zatem okiem na to, co ciekawego można z niego wyczytać – skupiłem się na moich przemyśleniach, sam raport jest sporo szerszy.
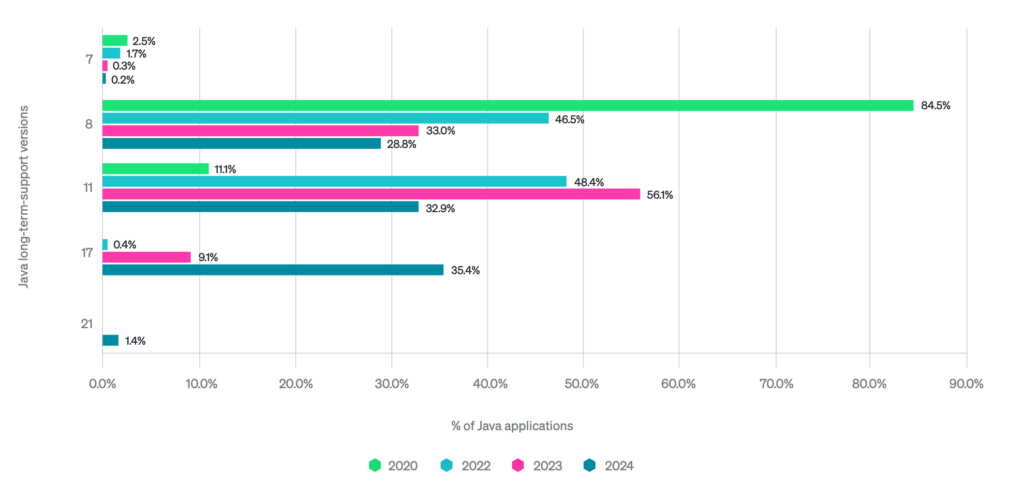
Raport mocno skupia się na szybszej adopcji JDK 21, niż JDK 17, ale te ich pojedyncze procenty to z mojej perspektywy i tak błąd statystyczny. Dużo ciekawszym jest chyba to, że jednak wzrosty użycia JDK 17 wydają się wynikać głównie z kanibalizacji JDK 11. Zakładając, że sam New Relic rośnie (13.48% growth year-over-year), można założyć, że w liczbach bezwzględnych ilość workloadów JDK 1.8 jest stabilna i większość projektów już na niej pozostanie.
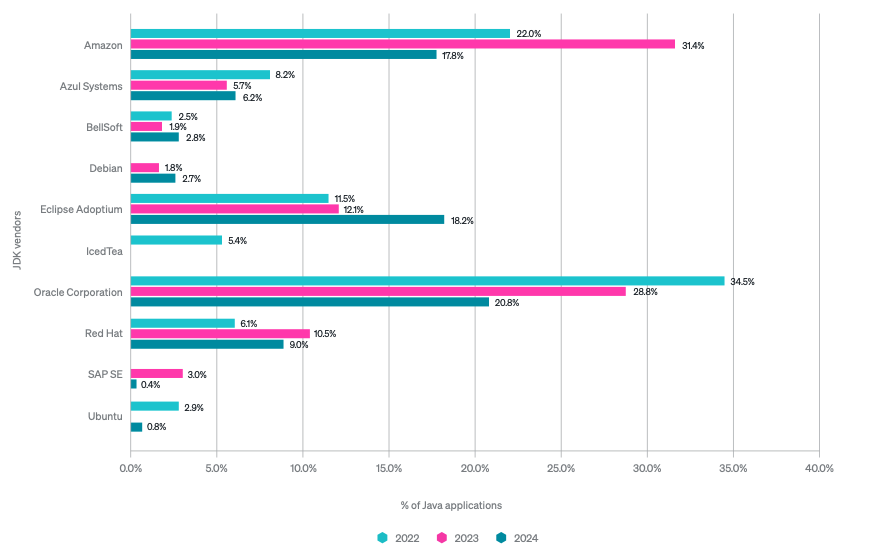
To co mnie osobiście szalenie cieszy, to jak mocno Adoptium przebija się do masowej świadomości. Sam zauważam, że powoli zwiększa się świadomość społeczności i firm, że Adoptium to nie jest jakiś obcy byt, a po prostu legitny wariant JDK, którego warto używać. Przy czym musze przyznać, że bardzo trudno jest mi zrozumieć tak dramatyczny spadek popularności Corretto i wygląda mi to raczej na jakiś błąd w raportowaniu wyników, metodologii – New Relic bazuje na telemetrii, więc możliwe, że Amazon wewnętrznie zaczął używać jakiegoś innego JDK i to tak zaważyło na usługach. New Relic – chętnie usłyszałbym czy macie na ten temat jakieś przemyślenia nie zawarte w raporcie.
Za bardzo interesującą uważam zaś obserwacje mówiącą o sporym rozjeździe między adopcją G1 jako domyślnego Garbage Collectora, a trendem redukcji CPU Core dostępnych dla aplikacji. Te dwa trendy pozostają ze sobą w kontrze, jako że G1 stworzone zostało do środowisk posiadających wiele rdzeni. To, czego raport New Relica nie pokazuje, to czy wzrosty obu tych tendencji rzeczywiście dotyczą tych samych aplikacji, ale podejrzewam, że nie wszyscy jednak przeczytali „drobny druczek”.

No i na sam koniec – zdecydowanie powinienem się zainteresować biblioteką Bouncy Castle. Dodałem ją do swojego prywatnego „radaru”.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Ostatnie szlify przed premierą Kotlin 2.0

Przeskoczmy sobie płynnie do Kotlina – widać bowiem, że przygotowania do wielkiej premiery K2 trwają i dostliśmy kilka interesujących ogłoszeń i publikacji. Pierwszą z nich jest oficjalny migration guide, który jest regularnie aktualizowany o zmiany w kolejnych wersjach RC Kotlin 2.0, a dodatkowo stanowi dobre wprowadzenie do nowych opcji syntaxu, które też zostały niedawno do Kotlina wprowadzone, dzięki czemu „załapały” się do poradnika dla osób chcących zmodernizować swój codebase.
To jednak nie jedyna z nowych publikacji od JetBrains. W ostatnich tygodniach ukazał się bowiem również tekst K2 Compiler Performance Benchmarks and How to Measure Them on Your Projects, nie tylko prezentujący benchmarki, ale też wyjaśniający techniczne powody zmian w charakterystyce wydajnościowej poszczególnych aplikacji. Zasadnicza zmiana w K2 (a głównie w jego frontendzie) polega na użyciu jednej zintegrowanej struktury danych zawierającej. Dzięki tej zmianie kompilator nie tylko zarządza jedną strukturą danych zamiast dwóch, ale również korzysta z dodatkowych informacji semantycznych, co usprawnia zarówno proces kompilacji, jak i analizę kodu w środowisku IntelliJ IDEA. Ta innowacja nie tylko zwiększają efektywność kompilacji, ale także ułatwiają implementację nowych funkcji językowych, szczególnie w kontekście dążenia do unifikacji obsługi różnych platform przez Kotlin Multiplatform, co stanowi jeden z głównych celów K2.

Według prezentowanych wyników, wydajność kompilatora Kotlin K2 prezentuje się imponująco, zwłaszcza w porównaniu do poprzedniej wersji. Prace nad nową architekturą kompilatora, która obejmowała przepisanie go od zera, zaowocowały znacznymi ulepszeniami w szybkości kompilacji. Zmiany te są szczególnie widoczne w różnych fazach kompilacji. Tekst od JetBrains podaje, że na przykład w projekcie Anki-Android czas kompilacji „od zera” (clean build) zmniejszył się z 57,7 sekundy w wersji 1.9.23 do 29,7 sekundy w wersji 2.0.0, co stanowi zysk na poziomie 94%. Podobne ulepszenia zaobserwowano w fazie inicjalizacji i analizy, gdzie zanotowano wzrost szybkości odpowiednio o 488% i 376%. Te usprawnienia wynikają z wdrożenia nowego algorytmu wnioskowania o typach oraz nowych backendów IR dla JVM i JS, co razem z nowym frontendem znacznie przyspiesza procesy kompilacji. Mimo tego, autorzy przestrzegają także o tym, że monitorować i dostosowywać procesy kompilacji, korzystając z narzędzi takich jak raporty budowania Kotlin, które pomagają zrozumieć i optymalizować czas kompilacji.
I bardzo słusznie, bo powyższe to dane od samych JetBrains, będących niejako sędzią we własnej sprawie – dlatego też fajnie, że zaczynają nam się pojawiać publikacje od osób zewnętrznych. W swojej szczegółowej recenzji nadchodzącej wersji Kotlin K2, Zac Sweers ze Slacka dzieli się swoimi spostrzeżeniami na temat ulepszeń K2, ale też wiążących się z nią wyzwań związanych. Patrzy na nie bez lukru i trzeźwo, podkreślając, że ostrzejsze wykrywania błędów w K2, szczególnie wokół obsługi nullowalności, z jednej strony obiecuje czystszych praktyk kodowania, z drugiej mogą wymagać od programistów reagowania na nowe ostrzeżenia czy błędy, co początkowo może być problematyczne. Sweers zwraca również uwagę na znaczące zmiany w obsłudze mechanizmów tłumienia kompilatora oraz wprowadzenie bardziej zaawansowanych możliwości rzutowania typów. Ponadto, ostrzega przed potencjalnymi problemami z integracją z Gradle, szczególnie w przypadku skomplikowanych lub wieloplatformowych projektów, podkreśla też konieczność dostosowania wtyczek kompilatora ze względu na aktualizacje interfejsu API między wersjami Kotlin.
Jeśli zaś chodzi o opisywaną przed chwilą wydajność, Sweers dzieli się mieszanką wyników na podstawie swoich testów, które kontrastują z obietnicami JetBrains o znaczących ulepszeniach out-of-the-box. Podczas gdy niektóre projekty mogą zauważyć skromne ulepszenia, inne doświadczają spowolnień, co sugeruje zmienny wpływ w różnych środowiskach. Przykładowo, eksperymenty w Slack wykazały obniżenie wydajności o około 17%, przynajmniej gdy wciąż używano KSP 1. W innym projekcie, CatchUp, zauważono znaczące ulepszenia, jednak kolejny projekt, Circuit, znowu doświadczył podobnych spowolnień. Podkreśla to konieczność przeprowadzenia własnych testów wydajności, aby w pełni zrozumieć, jak zmiany w K2 będą wpływać na ich projekty – każdy build jest nieco inny, a dzisiejszy proces kompilacji projektów jest na tyle skomplikowany, że nie każda aplikacja będzie cieszyć się z „darmowych” wzrostów wydajności. W wielu przypadkach będziemy musieli wziąć sposób tworzenia aplikacji pod lupę.
A to jeszcze nie koniec nowości na około Kotlina 2.0, Ben Trengrove i Nick Butcher z Google ogłosili bowiem, że od tego premiery tego wydania Jetpack Compose będzie teraz dołączony do repozytorium Kotlin, co zapewni, że Compose będzie na bieżąco aktualizowany do nowych wersji języka. Integracja ta eliminuje opóźnienia, z którymi deweloperzy wcześniej się mierzyli podczas aktualizacji Kotlin w aplikacjach Compose. Dodatkowo, wprowadzno nowy plugin Compose Compiler Gradle, który upraszcza konfigurację projektu za pomocą specjalnego DSL. Zespół Compose w Google będzie kontynuował rozwój kompilatora we współpracy z JetBrains.

A jak już mowa o Kotlinie, to wybieram się w tym roku na KotlinConf! W związku z tym spodziewajcie się szczegółowej relacji, będę się starał podsumowywać całość, pisząc relacje na bieżąco 😀
3. GraalSP – nowy statyczny profiler dla GraalVM

A teraz to co tygryski lubią najbardziej… czyli nowy Whitepaper. I to nie byle jaki, bo od zespołu GraalVM. Dopiero co skończyłem się przebijać przez ich oryginalne publikacje, a tutaj już wskoczyła nowa, dotycząca dalszych usprawnień profilowania… dodatkowo zmiksowanych z Machine Learningiem.
Ale zanim sobie przeskoczymy dalej, najpierw pora zdefiniować dwa terminy – profilowanie statyczne i profilowanie dynamiczne, czyli dwa różne podejścia do analizy i optymalizacji kodu w kontekście kompilacji Ahead of Time (AOT). Statyczne profilowanie, bazując na heurystykach i analizie strukturalnej kodu źródłowego przed jego wykonaniem, nie bierze pod uwagę danych wejściowych czy warunków wykonania. Chociaż jest skuteczne w wstępnej optymalizacji, jak inlining czy eliminacja martwego kodu, może nie uwzględniać wszystkich rzeczywistych scenariuszy użytkowania, co może prowadzić do suboptymalnej wydajności w nieprzewidzianych warunkach.
Dynamiczne profilowanie, z drugiej strony, odbywa się w czasie rzeczywistego wykonania programu i zbiera dane o jego zachowaniu za pomocą liczników w kluczowych punktach. Ta metoda pozwala na bardzo dokładne dostosowanie optymalizacji do faktycznych warunków pracy aplikacji, co jest korzystne w zmiennych środowiskach. Jednakże, dynamiczne profilowanie wymaga dodatkowego obciążenia wydajnościowego w czasie wykonania ze względu na potrzebę zbierania danych, co może wpłynąć negatywnie na czas odpowiedzi aplikacji. Dodatkowo, przygotowanie odpowiednich scenariuszy testowych samo w sobie jest wyczynem, o czym wie każdy kto kiedykolwiek „rozgrzewał” swoją aplikacje przed jej uruchomieniem na produkcji.

W zeszłym tygodniu ukazał się paper GraalSP: Polyglot, efficient, and robust machine learning-based static profiler, autorstwa Milan Čugurović, Milena Vujošević Janičić , Vojin Jovanović oraz Thomas Würthinger. GraalSP to nowe rozwiązanie powstałe w ramach GraalVM, radzi sobie z wyzwaniami związanymi z profilowaniem statycznym, wykorzystując machine learning) do efektywniejszego generowania profili. Dzięki zastosowaniu wysokopoziomowej grafowej reprezentacji pośredniej (będącej znakiem rozpoznawczym Graala), GraalSP jest zarówno portowalny, jak i poliglotyczny, co pozwala na jego zastosowanie w różnych językach kompilujących do bytecode’u Javy, takich jak Java, Scala czy Kotlin (czyli tak średnio poliglotyczny w stosunku do choćby Truffle, ale i tak odbiera pewnie masę roboty twórcom). Używa modelu XGBoost, który jest efektywniejszy od głębokich sieci neuronowych stosowanych w innych ML-opartych profilerach, minimalizując czas i złożoność kompilacji.
Dodatkowo, GraalSP wzbogaca swoją funkcjonalność o heurystyki predykcji prawdopodobieństwa gałęzi, które zapewniają wyższą wydajność skompilowanych programów, nawet w przypadku niedokładnych predykcji profilu. To zwiększa odporność (robustness) optymalizacji, minimalizując potencjalne negatywne wpływy na wydajność końcowej produktu. Takie podejście czyni GraalSP szczególnie wartościowym w dynamicznie zmieniających się środowiskach wykonawczych. Integracja GraalSP z kompilatorem Graal podobno demonstruje praktyczne korzyści tego rozwiązania, osiągając przyspieszenie czasu wykonania o średnio 7,46% w porównaniu do standardowej konfiguracji kompilatora.
Ogólnie polecam cały paper – jest dostępny dla wszystkich zainteresowanych. Spodziewam się, że już niedługo dostaniemy jakichś informacje o wciągnięciu projektu do głównej gałęzi, może już przy okazji GraalVM for JDK 23?

A jak już jesteśmy przy ogłoszeniach GraalVM, to czas przejść do Release Radaru.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
4. Release Radar

Graal Development Kit for Micronaut 4.3.7
Pamiętacie projekt Graal Cloud Native? Był to zestaw modułów stworzona w Oracle zaprojektowaną specjalnie do Micronauta, ułatwiający rozwój aplikacji chmurowych, oferując starannie dobrany zestaw modułów frameworka Micronaut. Moduły te były zaprojektowane do kompilacji Ahead-of-Time z użyciem GraalVM Native Image i miały na celu dostarczenie deweloperom niezależnych od platformy API i bibliotek obejmujących główne usługi chmurowe takie jak Oracle Cloud Infrastructure (OCI), Amazon Web Services (AWS) i Google Cloud Platform (GCP), z planowanym przyszłym wsparciem dla Microsoft Azure.
Projekt jest dalej rozwijany, ale wraz z nową wersją Graal Cloud Native został przemianowany Graal Development Kit for Micronaut. Zmiana ta była podyktowana opiniami użytkowników oraz pragnieniem lepszego związanie całości z brandem Micronauta, i klarowniej odzwierciedla teraz cel i wizji projektu. Szanuję prostotę i podejście na zasadzie kawa na ławę – tłumaczenie komukolwiek czym w ogóle jest Graal Cloud Native było szalenie problematyczne, teraz od wiadomo o co chodzi na pierwszy rzut oka. Zresztą, do konwencji nazewniczych Oracle jeszcze dzisiaj wrócimy.
Poza zmianą nazwy Graal Development Kit for Micronaut 4.3.7 Micronaut do wersji 4.3.7 (czy już wspominałem, że lubię jak rzeczy są proste i klarowne!), zapewniając kompatybilność między jego modułami a zależnościami, co pomaga w minimalizacji ryzyka niekompatybilności z ekosystemem bibliotek. Ponadto, Graal Development Kit obsługuje teraz zarówno Java 21, jak i Java 17, i zwiększył kompatybilność z opcjami dla kompilacji Ahead-of-Time pochodzącymi z Oracle GraalVM. Dodatkowo wydanie zawiera nowe przewodniki dotyczące tworzenia, wdrażania i uruchamiania funkcji serwerless na głównych platformach chmurowych, a także aktualizacje narzędzi deweloperskich i rozszerzeń dla środowisk takich jak IntelliJ Idea i Visual Studio Code.
Quarkus 3.10
Quarkus 3.10 to przede wszystkim usprawnienia w obsłudze warstwy danych, w tym nowy moduł POJO Mappera pochodzącego z Hibernate Search. Funkcja ta umożliwia bezpośrednie indeksowanie dowolnych obiektów POJO (Plain Old Java Objects), co ułatwia obsługę strukturyzowanych danych z różnych źródeł, takich jak pliki i encje MongoDB. Dodatkowo, Quarkus 3.10 aktualizuje swoją integrację z Flyway do wersji 10, co rozwiązuje wcześniejsze problemy z kompatybilnością z natywnymi wykonaniami oraz oferuje ulepszone narzędzia migracji bazy danych.
Wydanie to zawiera również zmiany w zarządzaniu konfiguracją dzięki uporządkowaniu parametrów konfiguracyjnych quarkus.package.*, co z jednej strony ułatwi rozszerzanie i utrzymanie w przyszłości ich rosnącego podzbioru, z drugiej zaś w niektórych przypadkach może wymagać ręcznie migracji. Quarkus 3.10.0 przynosi również aktualizacje Quarkus CXF, narzędzia umożliwiającego tworzenie i konsumpcję usług sieciowych SOAP.
Ostatni zestaw poprawek dotyczy Securit, które w Quarkus 3.10 doczekało się kilku usprawnieniom. Obejmują one możliwość wyboru mechanizmów uwierzytelniania dla endpointów REST za pomocą adnotacji, opcjonalne szyfrowanie ciasteczek sesji OpenIDConnect oraz wsparcie dla niestandardowej walidacji roszczeń JWT OIDC za pomocą zależności Jose4j oraz nowego walidatora TokenCertificateValidator.
Hibernate 6.5
A skoro w Quarkusie tyle nowości dotyczących baz danych, to warto przyglądnąć się też Hibernate 6.5, który między innymi wprowadza usprawnienia w obsłudze obiektów Java Time zgodnie ze specyfikacją JDBC 4.2. Wcześniej Hibernate zarządzał obiektami Java Time, używając pośrednich form java.sql.Date, java.sql.Time czy java.sql.Timestamp, a nowa aktualizacja umożliwia bezpośrednie przekazywanie obiektów takich jak OffsetDateTime, OffsetTime i ZonedDateTime, które zawierają jasno określone informacje o strefie czasowej. Ta zmiana zastępuje starsze metody, gdzie informacje o strefie czasowej nie były zachowywane z powodu ograniczeń wariantów java.sql.

Aktualizacja obejmuje również zmiany w konfiguracji pamięci podręcznej zapytań. Przejście z „płytkiego” na „pełne” reprezentowanie encji i kolekcji w wersji 6.0, (które miało na celu zmniejszenie liczby odwołań do bazy danych poprzez przechowywanie pełnych danych dla wyników fetch join w pamięci podręcznej zapytań) skutkowało bowiem zwiększonym zużyciem pamięci i potencjalnie większą aktywnością Garbage Collectora. Wersja 6.5 umożliwia więc użytkownikom konfigurację pamięci podręcznej – można to robić globalnie lub dla każdej encji/kolekcji, z lepszymi defaultami automatycznie wybierającymi między płytkim a pełnym układem cache w zależności od możliwości przechowywania danej encji/kolekcji, co zapewnia równowagę między wydajnością a efektywnością wykorzystania pamięci.
Ponadto, Hibernate 6.5 obsługuje teraz użycie rekordów Java jako @IdClass, co poprawia możliwości anotacji i upraszcza identyfikację encji.
record PK(Integer key1, Integer key2) {}
@Entity
@IdClass(PK.class)
class AnEntity {
@Id Integer key1;
@Id Integer key2;
...
}
Wersja ta zawiera również ulepszenia dla StatelessSession, takie jak wsparcie dla filtrów i logowania SQL, a dla Session i StatelessSession wprowadzonao także automatyczne włączanie filtrów. W zapytaniach UPDATE i DELETE można zaś teraz używać hibernatowych joinów. Bardzo przydatną nowością jest również możliwość ręcznego przypisywania identyfikatorów nawet wtedy, gdy są one annotowane za pomocą @Generator. Dodatkowo, pojawiła się też paginacja oparta na kluczach i klauzula ON CONFLICT dla zapytań insert, oferują większą kontrolę użytkownikowi.
Wydaniu towarzyszy też Hibernate Reactive 2.3, wspierający funckjonalności Hibernate ORM 6.5.
Devoxx Genie
Trwa sezon Devoxxów i pewnie za jakiś czas będziemy przebijać się przez konferencyjne wideo, ale w międzyczasie warto wspomnieć o projekcie Stephana Janssena, twórcy inicjatywy Devoxx(4kids). Stworzył on bowiem Devoxx Genie, który to jest pluginem do IntelliJ IDEA, zaprojektowany do współpracy zarówno z lokalnymi, jak i publicznymi LLMai (takimi jak OpenAI, Anthropic i podobne), przy wykorzystaniu popularnych narzędzi (takich jak Ollama, LM Studio czy GPT4All).
Jak pozostałe tego typu narzędzia, oferując funkcje takie jak wyjaśnianie kodu, jego review oraz automatyczne generowanie testów jednostkowych, czy rozmowy z chatem z poziomu IDE. Standard, ale to co jest wyjątkowo fajne to fakt, że w dobie zamkniętych rozwiązań Devoxx Genie jest w pełni otwartym projektem Open-Source i do tego napisanym w Javie, więc każdy może sobie zobaczyć jak został zbudowany. Polecam, jeśli lubicie sobie poczytać czasem kod, mnie aż zachęciło do reaktywowania mojej starej serii Github All-Star. Już któryś raz się odgrażam, może kiedyś w końcu coś z tym zrobię.
Ale to nie koniec Code Assistantów, ponieważ na samą górę dzisiejszego tortu zostawiłem sobie jeszcze jedną wisienkę…
Oracle Code Assist
A na końcu złamiemy zasady po raz kolejny zresztą (miała być zwyczajna edycja, a zamiast trzech sekcji są cztery… ale czego spodziewać się po tym, jak przez dwa tygodnie). Zaczęliśmy Radar od Oracle i na Oracle go zakończymy, a konkretnie zapowiedzią releasu… ale nie byle jakiego.
I tak mam pod tym kątem więcej honoru niż Nintendo, które flexowało się w tym tygodniu zapowiedzią zapowiedzi, choć i to nic przy branży filmowej, która robi teaser trailery do teaser trailerów.
Oracle zapowiedziało bowiem, że pracuje nad własnym Code Assistem. Oracle Code Assist (może mało kreatywnie, ale wolę to od „kreatywnego” nazewnictwa usług AWS) ma wyróżniać się na tle innych podobnych rozwiązań, takich jak GitHub Copilot czy Amazon CodeWhisperer (choć do tego jeszcze wrócimy), dzięki specjalizacji w językach Java i SQL oraz głębokiej integracji z infrastrukturą Oracle Cloud (OCI). Narzędzie zostało ponoć zaprojektowane, aby optymalnie wspierać specyficzne potrzeby programistów pracujących w ekosystemie Oracle.

Podczas gdy GitHub Copilot i Amazon CodeWhisperer oferują wsparcie dla szerokiego zakresu języków programowania, Oracle Code Assist koncentrować się ma na dostarczaniu wysoko dostosowanych sugestii kodu, które są typowe dla popularnych bibliotek Javowych, SQL, a także praktykami programowania specyficznymi właśnie dla rozwiązań Oracle. Ta specjalizacja ma pozwolić na bardziej precyzyjne i efektywne wsparcie w codziennej pracy deweloperów tworzących aplikacje korporacyjne. I wiecie co, ma to sporo sensu – pewnie Copilot nie nauczył się na GitHubie za wiele o JDK 1.7, EJB 1.0, Strutsach czy implementacji Enterprise Service Bus, więc taki fine-tunning może być kuszący dla niejednego przedsiębiorstwa.

Dodatkowo, Oracle Code Assist wprowadzi funkcję Retrieval Augmented Generation (RAG), która umożliwi bezpieczne łączenie kodu źródłowego organizacji i innych źródeł danych, zapewniając sugestie kodu bardziej dostosowane do specyficznych praktyk organizacji (choć wszyscy zdajemy sobie sprawę, że to akurat nie zawsze będzie zaletą, prawda?). Mimo wszystko, tego typu funkcjonalność jest rzadkością wśród innych asystentów kodowania, co daje Oracle przewagę w kontekście zastosowań korporacyjnych i regulowanych sektorów, gdzie takie dostosowanie do specyficznych potrzeb jest szczególnie wartościowe.
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


