Dzisiaj powracamy do formy tekstowej, z nowymi Jepami, proposalami i mega ciekawym Release Radarem.
1. Nowe JEPy – usprawnienia CDS, Generacyjny ZGC i Markdown w dokumentacji

JEP draft: (draft) Unified storage for application cache (aka „new CDS workflow”)
Rzadko kiedy informuje o JEP-ach na tak wczesnym etapie, ale ten mi się szczególnie spodobał. „Unified storage for application cache (aka „new CDS workflow)” ma na celu unifikację miejsca przechowywania danych pamięci podręcznej aplikacji, będące nową iteracją mechanizmu Class-Data Sharing. Celem jest rozwinięcie wykorzystania CDS, w tym momencie używanego do przechowywania metadanych klas i obiektów sterty, aby mogło być używane jako cache dla szerszego zakresu typów danych, takich jak np. metody skompilowane AOT. Planowane jest również uporządkowanie sposobu obsługi CDS (który na przestrzeni lat rozwinął się w sposób ad hoc) poprzez wprowadzenie pojedynczej flag -XX:CacheDataStore, który określa lokalizację magazynu. Początkowo magazyn będzie składał się z jednego pliku, ale w przyszłości może odnosić się do wielu plików, potencjalnie hierarchicznych.
Na razie to wszystko co wiemy na tym wczesnym etapie, więc szczegóły mogą się jeszcze zmienić. W dalszym ciągu daje nam podgląd na to, w jaki sposób w przyszłości będą łączyć się różne mechanizmy usprawniające cold start aplikacji.
JEP draft: Deprecate Non-Generational ZGC
Kontynuując temat draftów, kolejna z ciekawych nowości to „Deprecate Non-Generational ZGC”. Dopiero co do ZGC wprowadzono Generacyjny wariant ZGC, a już w tej chwili pojawiają się plany na deprekacji wersji niegeneracyjnej, z zamiar usunięcia jej w przyszłych wydaniach. Głównym celem jest redukcja kosztów utrzymania oraz technicznego długu wynikającego z obsługi dwóch różnych trybów działania. Non-Generational ZGC, mimo że nie zostanie usunięty w ramach tego JEP-u i pewnie zostanie z nami na dłużej, to stanie się tym mniej preferowanym trybem, gdyż Generational ZGC, wprowadzony w JEP 439, jest postrzegany jako lepsze rozwiązanie w większości use casów.
JEP 467: Markdown Documentation Comments
JEP 467 to zaś wreszcie JEP-kandydat, którego celem jest umożliwienie pisania dokumentacji JavaDoc w Markdownie, zamiast wyłącznie w mieszance HTML i tagów JavaDoc. Powiedzmy sobie szczerze, Markdown od lat jest rozwiązaniem, które króluje jeśli chodzi o tworzenie dokumentacji technicznej i de facto stał się standardem do tego stopnia, że w zasadzie każde IDE czy Code Editor mają do niego świetne wsparcie.

Celem jest oczywiście ułatwienie pisania i czytania komentarzy API. Tworzenie dokumentacja to trudny, żmudny proces niezależnie od wybranego markupu, a konieczność stosowania HTML (ergo języka quasi-XML-owego), który jest mniej intuicyjny dla ludzi, nie pomaga. Ostatnimi czasy widać trend, że i częściej generowany z innych języków znaczników bardziej „przyjaznych” dla człowieka. Markdown nie dość że jest popularnym językiem znaczników dla prostych dokumentów, łatwym do czytania, tworzenia i przekształcania w HTML, co czyni go idealnym wyborem dla komentarzy dokumentacyjnych, które zazwyczaj nie są skomplikowanymi dokumentami strukturalnymi… i chyba nie chcielibyśmy, żeby się takimi stały.
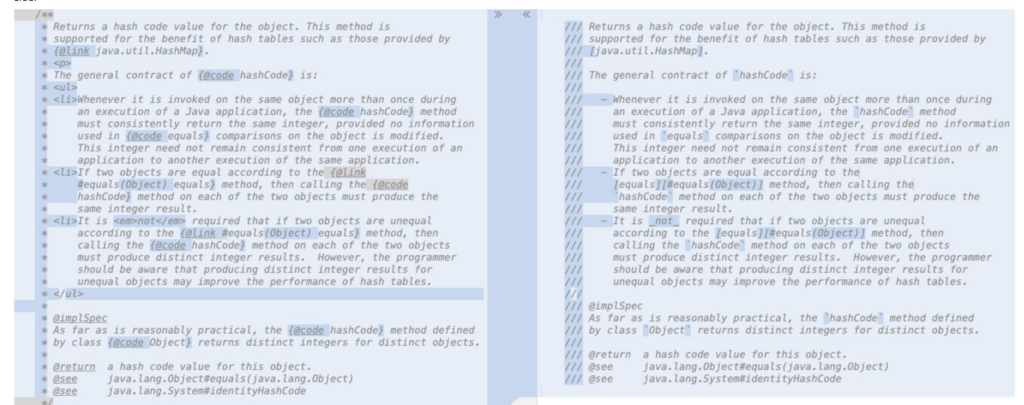
Jak to ma działaś w praktyce? Na przykładzie komentarza dla metody hashCode można zauważyć różnicę w użyciu Markdown, gdzie linie zaczynają się od /// zamiast tradycyjnego /** ... */. HTML nie jest wymagany do wskazania przerwy akapitowej; wystarczy pusta linia. Elementy HTML takie jak <ul> i <li> są zastępowane przez znaczniki listy punktowanej Markdown, używając - do wskazania początku każdego elementu listy. Zamiast <em>, używa się podkreśleń (_) do wskazania zmiany czcionki, a instancje tagu {@code ...} są zastępowane przez znaki odwrotnego apostrofu (`) do wskazania czcionki o stałej szerokości.
Dawno chyba też żaden z JEP-ów nie był tak mocno dyskutowany na redditcie. Opinia społeczności poza ogólnym entuzjazmem (bo taki na pewno towarzyszy rozwiązaniu) ujawnia kilka głównych obaw. Po pierwsze, wielu uważa wymóg stosowania trzech ukośników dla komentarzy dokumentacyjnych za niewygodny, sugerując próbę wypracowania jakiejś bardziej zwięzłej notacji – i tu się mocno podpisuje, choć fakt, że wszystkie linie mają taki sam prefix z drugiej strony wpływa na czytelność. Dodatkowo, dyskusja porusza obawy dotyczące długoterminowej żywotności i elastyczności takiego wyboru składni (trzech slashy), zastanawiając się, co stanie się, jeśli nowy język znaczników zyska na popularności w przyszłości (w rozmowę zaangażował się sam Ron Pressler). Wytykany jest też brak jakiejś sensownej alternatywy dla tagów JavaDoc, które dalej muszą być mieszane z Markdownem w swojej klasycznej formie. Mimo powyższego feedbacku, odbiór jest pozytywny, a biorąc pod uwagę, że to już kandydacki JEP, a nie np. Preview, to nie spodziewam się już jakichś daleko idących zmian.

Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Triton – Kolejne podejście do programowania na GPU z Project Babylon

A teraz po raz kolejny w tym roku przyglądniemy się projektowi Babylon. Niedawno bowiem ukazała się publikacja Paula Sandoza Exploring Triton GPU programming for neural networks in Java, czyli kolejna próba wykorzystania Code Reflection do rozepchania się łokciami w przestrzeni około-AI.
Triton to domenowy model programowania i kompilator, który umożliwia programistom piszącym w Pythonie tworzenie kodu działającego na procesorach GPU, nawet tym mający niewielkie doświadczenie w pracy z GPU i językami programowania specyficznymi dla GPU, takimi jak CUDA. Ukrywa on bowiem przed programistami bazujący na wątkach model programowania CUDA, co pozwala kompilatorowi Triton lepiej wykorzystać sprzęt GPU, na przykład poprzez optymalizację przypadków, które mogłyby inaczej wymagać jawnej synchronizacji. Dodatkowo, dzięki abstrakcji Tritona programiści operują na tensorach zamiast skalarnych wartości, co znacząco upraszcza i przyspiesza proces tworzenia kodu na GPU.
Triton działa jednak z Pythonem, ale i dla Javy okienko transferowe na wykorzystania modelu programowania Triton otwiera się dzięki Code Reflection, rozwijanej w ramach Project Babylon. Dla przypomnienia Refleksja kodu pozwala na symboliczne reprezentowanie programów Java, co umożliwia ich analizę i automatyczną transformację na model kodu Triton. Dzięki temu programy napisane w Javie mogą być kompilowane do kodu działającego na GPU, podobnie jak to ma miejsce w przypadku Pythona z użyciem Tritona. Projekt Babylon w tym kontekście działa jako most między Javą, a specyficznymi rozwiązaniami pod GPU, otwierając programistom drzwi do świata programowania GPU z wszystkimi jego korzyściami, takimi jak rozszerzone możliwości obliczeń równoległych w dużej skali.
Na poziomie technicznym, proces ten zaczyna się od utworzenia modelu kodu Java za pomocą refleksji kodu, który następnie jest analizowany i transformowany w model kodu Triton. W tym procesie następuje przypisanie odpowiednich typów do elementów modelu, co umożliwia dokładną transformację kodu Java na kod odpowiedni dla GPU, aby wyprodukować formę podobną do Triton MLIR.

Jeśli jesteście ciekawi dodatkowych detali, w artykule pojawiają się przykłady, gdzie na przykładzie dodawania wektorów pokazano, jak implementacja w Javie może być zbliżona do Pythonowej, mimo np. braku przeciążania operatorów w Javie. Więcej szczegółów znajdziecie w oryginalnej publikacji.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
3. Release Radar

Quarkus 3.8
Zacznijmy sobie od Małyc-Dużych zmian w Quarkusie. Wersja 3.8 został ogłoszony nową wersją Long-Term Support (LTS). A czemu Mało-Duże? Nowa wersja to bezpośrednio kontynuuje gałąź 3.7 i tym samym nie zawiera żadnych nowych funkcji wychodzących poza 3.7, co najwyżej zawiera kilka dodatkowych poprawek, wśród których warto wymienić zaadresowanie CVE-2024-1597 związanego z sterownikiem JDBC PostgreSQL. Jeśli jednak dalej pozostajecie na ostatnim LTS, którym była jeszcze wersja 3.2, to nowe wydanie będzie dla Was sporym przeskokiem – ulepszenia OpenTelemetry, wsparcie dla Java 21 (plus minimalna wspierana nowa wersja to teraz JDK 17), wsparcie dla OpenIDConnect i sporo innych usprawnień.
Scala 3.4.0
Paweł Marks z VirtusLab poinformował o wydaniu nowej wersji Scali – Scala 3.4. Wśród najważniejszych nowości w nowym wydaniu z pewnością należy wymienić stabilizacje ważnych SIP-ów:
- SIP-54 – upraszczający importowanie Extension Methods z różnych źródeł
- SIP-53 – zwiększający ekspresyjność wzorców typów.
- SIP-56 – usprawniający inferencje typów, szczególnie dla funkcji takich jak
fold.
Co więcej, Scala 3.4.0 wprowadza ulepszenia w backendzie, optymalizując polimorficzne lambdy przez wykorzystanie lambd pochodzących z JVM, co uniezależnia Scalę od anonimowych klas. Nowa wersja ulepsza też raportowanie błędów, w tym bardziej informacyjne komunikaty dla niekompatybilnych wersji TASTy.
Scala 3.4.0 wprowadza też eksperymentalną adnotację @publicInBinary, która umożliwia oznaczanie niektórych definicji jako części API binarnego. Wersja deprecjonuje też nieaktualne konstrukty, takie jak wildcardy typów _ i private[this] (oraz kilka innych), na rzecz nowocześniejszych i bardziej zwięzłych alternatyw. Ogólnie zachęcam zajrzeć do oryginalnych Release Notes, gdyż ciekawych detali dla użytkowników Scali jest tam więcej.
Rainbow Gum
A teraz mam prawdziwą ciekawostkę od twórców jstachio, frameworku będącego opisywanym już tu kiedyś systemem templatingu w Javie opartym o mustache. Rainbow Gum bierze sobie bowiem za cel poradzić sobie złożoność i nieefektywność obecnych frameworków logowania w Javie, zwłaszcza w kontekście aplikacji z bardzo szybkim startem. Tradycyjne frameworki logowania takie jak Log4J 2 i Logback są nie tylko obciążone funkcjami, które mogą nie być niezbędne dla wszystkich aplikacji, ale także polegają na zewnętrznych plikach konfiguracyjnych, które mogą spowalniać inicjalizację aplikacji i zwiększać ryzyko bezpieczeństwa, jak pokazała podatność Log4Shell.

Tworzy to potrzebę bardziej uproszczonego, prekonfigurowanego rozwiązania do logowania, które nie mając na karku wielu lat rozwoju może szybko dostosować się do nowych funkcji Javy i mnogości środowisk uruchomieniowych.
Rainbow Gum to właśnie taka lekka implementacja SLF4J dla JDK 21+, która ma na celu być łatwiejszą w użyciu, wykorzystując przy tym nowsze technologie JDK. Rainbow Gum nie oferuje tyle elastyczności co Logbacka czy Log4J, ale upraszcza konfigurację i inicjalizację. Rainbow Gum jest zaprojektowany tak, by być przyjaznym dla kompilacji natywnych Graal VM. Umożliwiając konfigurowanie całości za pomocą kodu aplikacji, Rainbow Gum pozwala programistom wykorzystywać unikać pułapek związanych z zewnętrznymi plikami konfiguracyjnymi, prowadząc do szybszego startu aplikacji i zmniejszenia przestrzeni na podatności.
public class GettingStartedExample implements RainbowGumProvider {
@Override
public Optional<RainbowGum> provide(LogConfig config) {
return RainbowGum.builder(config)
.route(r -> {
r.level(Level.DEBUG, "com.myapp");
r.appender("console", a -> {
a.encoder(new PatternEncoderBuilder("console")
.pattern("[%thread] %-5level %logger{15} - %msg%n")
.fromProperties(config.properties())
.build());
});
})
.optional();
}
}Jego projekt jest celowo modularny i minimalistyczny, równocześnie wspierają dość zaawansowane funkcje jak kolorowane logów i czy wsparcie dla JSON.
Ciekawe, czy Rainbow Gum to zapowiedź jakiegoś nowego trendu bibliotek opytmlizowanych pod specyfikę użycia z GraalVM.
Coat
A na koniec Coat, który jest kolejnym z przedstawicielem mojej ulubionej kategorii małych bibliotek, odpowiadających na konkretny problem. Ten który rozwiązuje Coat polega na potrzebie efektywnego i „typesafe” zarządzania danymi konfiguracyjnymi. Tradycyjnie, odczytywanie i integrowanie takowych za aplikacją wiąże się z ręcznym parsowaniem, walidacją i konwersją na potrzebne struktury, co jest podatne na błędy i uciążliwe. Manualność procesu zwiększa ryzyko błędów i niespójności, szczególnie w złożonych aplikacjach, gdzie konfiguracja często się zmienia lub wymagana jest jej walidacja według konkretnych kryteriów. Dodatkowo, programiści często muszą pisać specjalne mappery, aby zapewnić, że wartości konfiguracyjne odpowiadają oczekiwanym typom.
@Coat.Confg(converters = {
UuidConverter.class,
CurrencyConverter.class,
})
public interface AppConfig {
public UUID uuid();
public Currency currency();
}
final AppConfig config = new ImmutableMyConfig(new File("/path/to/config.properties"));
try {
config.validate();
} catch (final ConfigValidationException ex) {
System.err.println("Error in config file:\n" + ex.getValidationResult().toString());
System.exit(1);
}
final UUID appName= config.uuid();
final Currency currency= config.currency();Coat oferuje rozwiązanie powyższych problemów poprzez swój procesor adnotacji, który generuje klasy do odczytywania wartości konfiguracyjnych do typowanych obiektów. Poprzez zdefiniowanie interfejsu z oczekiwaną strukturą danych konfiguracji i użyciu odpowiedniej adnotacji, Coat automatycznie tworzy konkretne implementacje.
Obsługują parsowanie, walidację i konwersję typów wartości konfiguracyjnych. Coat, nie wymaga runtime’owych zależności i obsługuje Java 11 lub wyższą.
A na końcu podzielę się nowym hobby!
Bo kiedy świat gra w Final Fantasy VII Rebirth, a ty nie grasz, bo zajmujesz się trzyletnią córką chora na zapalenie płuc i ona mówi: „Tato, zróbmy coś z gliny.”…

…włącza się wtedy kreatywność.
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


