W dzisiejszej edycji długo oczekiwana premiera Quarkusa, aktualizacja AWS Lambda, a także JEP oraz mailing prezentujące pewne mało znane detale Javy.

1. Quarkus dostaje wydanie 3.0
Uwielbiam Quarkusa i całą stojącą za nim filozofię opartą o stworzenie nie tylko samego (wydajnego) frameworki, ale również zestawu narzędzi, który pozwoli na jego efektywne użycie. W świecie, gdzie Spring Boot ma (zasłużenie, AD 2023 to też świetny framework jest) dominującą pozycję, miło widzieć realną konkurencje, która wybrała sobie swoją niszę i się w niej rozpycha (aplikacje strikte Cloud Native, łącznie z funkcjami serverless, w których wsparciu akurat bije javowego Goliata). Jako, że historycznie miałem też sporo doświadczenia z platformą Java EE, w dalszym ciągu ciężko mi uwierzyć, jak wiele pracy wykonano, by pozbyć się złej sławy standardu, a RedHat z pewnością dołożył do tego cegiełkę. Dlatego też na Quarkus 3.0 czekałem z niecierpliwością, ponieważ poza standardowymi zmianami, zgodnymi z kierunkiem w którym idzie cały ekosystem (Jakarta EE 10, MicroProfile 6.0, Hibernate 6.0 i Reactive czy zapowiedź porzucenia wsparcia dla JDK 11) dokłada on kilka swoich własnych, unikalnych smaczków.
Zacznijmy od Dev UI, które z jednej strony pokazuje pewne korzenie Quarkusa – tego typu cudeńka to raczej zawsze były domeną serwerów aplikacyjnych, z drugiej zaś uzmysławia, jak wiele dobrych pomysłów istniało w takich wydawałoby się antycznych już rozwiązaniach – dość wymienić panel do zmienianie opcji konfiguracyjnych czy zarządzaniu rozszerzeniami. I oczywiście, Dev UI pojawiło się już przy okazji Quarkusa 2.0, ale teraz zostało znacznie rozbudowane i wygodniejsze w obsłudze. Mający doświadczenie z rozwiązaniami frontendowymi szybko rozpoznają też drugiego rodzica tego rozwiązania – dzięki temu, że Quarkus można uruchomić w tak zwanym Dev Mode, dostępne są takie featury jak Continouse Testing (uwierzcie mi, it makes a difference). I oczywiście nie jest tak, że Quarkus jako jedyny posiada takie możliwości, ale jest to jedyny z popularnych frameworków, który traktuje je jako obywateli pierwszej kategorii, a nie jako dodatek – i to czuć.
Niezwykle interesującą zmianą jest też wprowadzenie Mutiny2. Mutiny to biblioteka Java opracowana przez zespół Quarkus w celu uproszczenia implementacji programowania reaktywnego i asynchronicznego. Jak to bywa w wypadku projektów Quarkusa, została zaprojektowana tak, aby był intuicyjne i proste podejście do pisania kodu reaktywnego w porównaniu do innych bibliotek, takich jak RxJava i Project Reactor. Mutiny podobnie jak wymienione przed chwilą projekty jest implementacją Reactive Streams. Dla tych którzy mogą nie kojarzyć, Reactive Streams API jest standardem dla asynchronicznego, nieblokującego i świadomego backpressure przetwarzania strumieni danych w Javie, promując interoperacyjność wśród bibliotek i frameworków programowania reaktywnego. W okolicach JDK 9 był to jeden z najgłośniejszych tematów w całym JDK, ale jako że hype na programowanie reaktywne nieco już minął, przestały się też jak grzyby po deszczu pojawiać kolejne implementacji. Dlatego też Mutiny postanowiło odpuścić sobie „do abstrakcji” Reactive Streams, a zamiast tego użyć po prostu referencyjnej wersji z JDK – java.util.concurrent.Flow. Jest to chyba pewne symboliczne domknięcie pewnej epoki.
Czego mi jednak zabrakło? Miałem nadzieje, że dostaniemy jakieś szersze wsparcie wirtualnych wątków, które było wspomniane w momencie ogłoszenia prac nad wersją 3.0. Zrobiłem sobie małe review kodu i na ten moment w dalszym ciągu najciekawszym fragmentem wsparcia VirtualThreads w pozostaje rozszerzenie do resteasy-reactive, które zresztą nie wyewoluowało jakoś mocno od czasu oryginalnej publikacji rok temu przy okazji JDK 19. Obrazuje ono zresztą bardzo dobrze, jak bardzo defensywnym jest dzisiaj programowanie wsparcia dla sztandarowego dziecka Looma: Zobaczcie zresztą sami lekko uproszczony przykład, oryginalną klasę znajdziecie tutaj:
private boolean isRunOnVirtualThread(MethodInfo info, BlockingDefault defaultValue) {
boolean isRunOnVirtualThread = false;
(...)
Map.Entry<AnnotationTarget, AnnotationInstance> transactional = getInheritableAnnotation(info, TRANSACTIONAL);
if (transactional != null) {
return false;
}
if (runOnVirtualThreadAnnotation != null) {
if (!JDK_SUPPORTS_VIRTUAL_THREADS)
{
throw new DeploymentException((...))
}
if (targetJavaVersion.isJava19OrHigher() == Status.FALSE) {
throw new DeploymentException((...))
}
isRunOnVirtualThread = true;
}
if (defaultValue == BlockingDefault.BLOCKING) {
return false;
} else if (defaultValue == BlockingDefault.RUN_ON_VIRTUAL_THREAD) {
isRunOnVirtualThread = true;
} else if (defaultValue == BlockingDefault.NON_BLOCKING) {
return false;
}
if (isRunOnVirtualThread && !isBlocking(info, defaultValue)) {
throw new DeploymentException((...))
} else if (isRunOnVirtualThread) {
return true;
}
return false
}
Także jeżeli kiedykolwiek czuliście się źle, używając masy zagnieżdżonych if-ów, to mam nadzieje, że widzą powyższe jest Wam już trochę lepiej.
Źródła
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Amazon rozpycha się coraz szerzej ze swoim JDK
Ok, to jak już mamy zaliczonego najnowszego Quarkusa, czas przyglądnąć się szerszemu obrazkowi – ostatnimi tygodniami pojawiły się dwa raporty, które próbują opisać nam szerszy obrazek tego, jak na świecie wygląda tworzenie aplikacji Javowych – 2023 State of the Java Ecosystem od New Relic oraz 2023 State of Java in the Enterprise Report, sygnowany logiem Vaadina.
Z góry powiem, że stwierdzenie kończący poprzedni akapit jest tu trochę tutaj naciągane, ponieważ oba raporty zostały stworzone przez konkretne podmioty i to czuć. Szczególnie zabawne jest to w wypadku State of Java in the Enterprise – podejrzewam, że dla większości z Was te przeglądy to jedyne miejsce w sieci, gdzie jeszcze trafiacie na jakiekolwiek ślady Vaadina, a Raport przedstawia go jako technologie zdecydowanie wschodzącą (przykładowo, 34% respondentów Vaadin Flow używa „w znacznym stopniu”). Przynajmniej twórcy się z tym nie kryją – w każdym możliwym miejscu dodają disclaimer, że badanie było przeprowadzone wśród marketingowej bazy Vaadina, co z wiadomych powodów zaburza sporo wyników.
Zamiast przyglądać się więc na standardowych, tych samych w zasadzie trendach – jak zwykle coraz większą adopcje mają nowe LTSy Javy, widząc też stałą, ciągłą adopcje chmury obliczeniowej (choć wydaje mi się, że łatwo już było, a sporo aplikacji które do tej pory do Amazonów tego świata do tej pory nie trafiło umrze w firmowych datacenter) – skupie się na najciekawszym fakcie, wynikającym z każdego z raportów.
Jeżeli chodzi o raport Vaadina, to on sam w sobie nie jest jakoś zbyt rewolucyjny. W dokumencie bardzo dużo mówi się o modernizacji aplikacji, a łącząc ze sobą wnioski z kilku różnych wykresów dojść można do wniosku, że wiele firm (i to głównie w Europie, gdyż zdecydowanie większość respondentów pochodzi ze Starego Kontynentu) coraz poważniej podchodzi do tematu modernizacji, a największym wyzwaniem jest… UX aplikacji i ogólnie warstwa frontendowa. Ponownie, całość może być mocno skrzywiona ze względu na grupę badawczą (Vaadin zawsze pozycjonował się na Framework FullStackowy), ale widać, że nawet w przypadku aplikacji wewnętrznych (64% respondentów tworzy takowe) sporo nacisku kładzie się dziś na ten właśnie aspekt. Szkoda, że twórcy nie podzielili się Raw Data – bardzo chętnie zobaczyłbym, czy istnieje korelacja min. wielkością firmy a wybieranym frameworkiem frontendowym – takich właśnie krzyżowych zestawień mi najbardziej zabrakło.
Ale przyznam, że tego Vaadina to przedstawiłem Wam tak bardziej dla kompletności. O wiele ciekawiej prezentuje się bowiem State of the Java Ecosystem New Relica. Oczywiście, posiada on większość wad swojego poprzednika – New Relic to usługa pomagająca w telemetrii aplikacji, dlatego to właśnie w oparciu o dane zbierane przez użytkowników produktu powstał dokument. Prawdopodobnie nie oddaje to całego ekosystemu, jak raczyłby sugerować tytuł. Z tym jednak przychodzi pewien interesujący twist – zamiast danych deklaratywnych, zebranych z pomocą ankiety, mamy tutaj do czynienia z realnymi wartościami produkcyjnymi. Nie dowiemy się więc nic o planach i wyzwaniach (jak to było w wypadku Vaadina), ale możemy poznać sporo szczegółów „bliskich maszyny”.
Stąd też raport New Relica to przede wszystkim technikalia, ale po to pewnie tutaj wchodzicie, prawda? Bardzo dużo miejsca poświęcono min. konteneryzacji, która staje się powoli standardem jeśli chodzi o sposób releasowania javowych aplikacji, a w raporcie znajdziemy sporo interesujących detali jak ilość użytych procesorów czy pamięci (TLDR: sprawdźcie swoje ustawienia Waszych kontenerów, bo dane pokazują, że sporo programistów ma złe ustawienia. To co jednak najbardziej przyciąga wzrok, to wykres użycia konkretnych wersji JDK. Tutaj bowiem wyniki, zwłaszcza w porównaniu do roku 2022 są… interesujące:
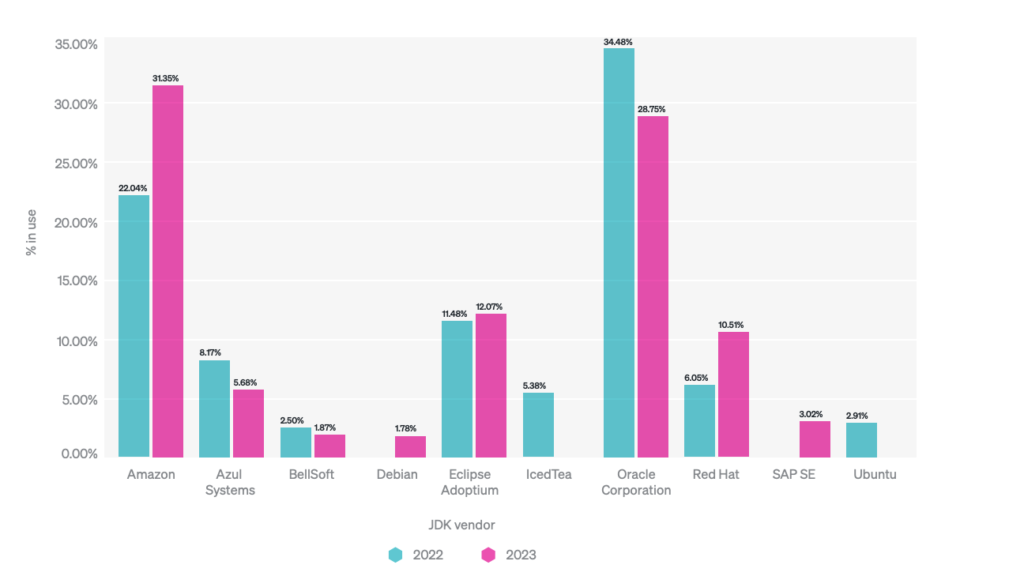
Oczywiście, wyniki z pewnością są w jakimś stopniu zbiasowane ze względu na bazę użytkowników New Relica, ale trend jest wyraźny – coraz więcej osób wybiera właśnie Amazonowe Corretto jako swoje produkcyjne JDK. O ile większość JDK jest do siebie dość podobne, Corretto to runtime z dodatkowymi „twistami” – przykładowo, jest ono dodatkowo zoptymalizowane pod kątem działania na procesorach ARM (a zwłaszcza AWS-owego ). Jako jedyne wspiera również SnapStart, czyli ogłoszoną w zeszłym roku metodę redukcji Cold Startu funkcji Serverless. Dla tych, którzy takowego nie kojarzą, ze względu na ilość niuansów polecam lekturę nieco szerszego opracowania tematu w jednej z naszych poprzednich edycji. I choć nie znam za wielu przypadków użycia Corretto poza AWS-em, to jednak widać, że inwestycje dostawców chmurowych we własne JDK wydają się mieć dla nich sens, także dzięki możliwości zaproponowania dodatkowych innowacji.
A możliwe, że Corretto tylko będzie zyskiwać na popularności, AWS bowiem nie zaprzestaje inwestycji we wsparcie Javy w swojej chmurze. W zeszłym tygodniu pojawiło się duże ogłoszenie dotyczące AWS Lambda – usługa Serverless Amazonu doczekała się bowiem wsparcia najnowszego LTS, czyli JDK 17. Jak łatwo się domyśleć, całość napędza właśnie Corretto. „Natywne” wsparcie najnowszego LTS-a oznacza też, że można będzie wreszcie używać z tą wersją AWS SnapStart wraz z nową Javą.

A jeśli jesteście podcastowi, ciekawą dyskusje na temat Javy w Amazonie znajdziecie w ostatnim odcinku airhacks.fm Adama Biena, w którym gościł on Maximiliana Schellhorna, Soultion Architecta zajmującego się właśnie Java Serverless w AWS.
Żródła
- State of the Java Ecosystem
- State of Java in the Enterprise
- The road to AWS Lambda SnapStart – guide through the years of JVM „cold start” tinkering – JVM Weekly #24
- AWS Lambda now supports Java 17
- Podcast airhacks.fm: Serverless Java (17) on AWS
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
3. Rzut oka pod maskę Javy – Dynamiczni Agenci i „tearing”
Tydzień temu, pisząc o zatwierdzonych JEP-ach obiecałem Wam, że do tematu wrócimy w kolejnej edycji. Zgodnie z zapowiedzią, przyglądnijmy się teraz Prepare to Restrict The Dynamic Loading of Agents, które niedawno zostało opublikowane jako JEP Draft. Dokument ten proponuje zmiany w sposobie ładowania Agentów Java do już działającej JVM w celu zapewnienia lepszego bezpieczeństwa. Już niedługo będzie się to kończyło komunikatem z ostrzeżeniem. Długoterminowym celem jest jednak przygotowanie społeczności na przyszłe wydania JDK, które domyślnie wyłączą ładowanie agentów do działającej JVM.
Agenci Java to komponenty, które mogą modyfikować kod aplikacji podczas jej działania, wykorzystywane przede wszystkim do profilowania i monitorowania (to właśnie z ich Agenta pochodzą dane, które prezentował Raport New Relica z poprzedniej sekcji). Zostały wprowadzone w Javie 5, i mogą być tworzone za pomocą API java.lang.instrument lub JVM Tool Interface. Przez lata instrumentacja JVM była rozwijana min. dzięki Attach API, wprowadzone w JDK 6, pozwala narzędziom właśnie na podłączenie się do działającej JVM. Niektóre narzędzia używają Attach API do właśnie dynamicznego ładowania agentów.
W JDK 21 dynamiczne ładowanie agentów będzie nadal dozwolone, ale pojawi się wspomniane ostrzeżenie. Aby go, użytkownicy muszą przekazać -XX:+EnableDynamicAgentLoading w linii poleceń. W przyszłych wydaniach, dynamiczne ładowanie agentów będzie domyślnie zabronione i zakończy się błędem, jeśli próba zostanie podjęta bez tej właśnie opcji. Żadne zmiany nie są równocześnie planowane wobec narzędzi, które ładują agentów podczas uruchamiania maszyny wirtualnej lub używają Attach API do celów innych niż ładowanie agentów lub biblioteki .
A jak już jesteśmy przy tekstach przedstawiających proces decyzyjny za konkretnymi fragmentami Języka, to nie Mógłbym sobie odmówić podzielenia się z Wami On atomicity and tearing, autorstwa Briana Goetza. Ten pochodzący z listy mailingowej Javy wywód omawia atomowość, nieatomowość i tak zwany tearing (rozdarcie) w kontekście Projektu Valhalla w Javie, który ma na celu umożliwienie „spłaszczenie” sposobów przechowywania obiektów na stercie.
Tearing odnosi się do instancji, w której wartość jest odczytywana lub zapisywana w częściach, powodując niespójność w odczytywanych wartościach – w tekście przywoływany jest przykład przechowywania w pamięci liczby 64-bitowej jako dwie wartości 32-bitowe. Z tego względu przy dostępie do nich w rzadkim przypadku może wystąpić tak zwany „race condition”. Jest to kompromis osiągnięty w celu zapewnienia dobrej wydajności dla operacji numerycznych w czasach, gdy zmienne 64-bitowe nie były jeszcze wydajnie obsługiwane przez procesory.
Teraz problem wraca w kontekście innych typów danych – często znacznie większych niż 64-bity – które w wypadku Valhalli również mogą podlegać „rozrywaniu”.
Tekst przedstawia trzy wybory dla Valhalli dotyczące podejścia do tego problem:
- Nigdy nie zezwalaj na „rozrywanie” wartości, jak w int.
- Zawsze zezwalaj na „rozrywanie” wartości w czasie race-condition, podobnie jak w przypadku long.
- Stworzyć rozwiązanie, które pozwoli programiście wybrać strategie
Najbezpieczniejszym wyborem jest nigdy nie zezwalanie na rozdarcie, ale to ograniczyłoby cele Valhalli. Goetz sugeruje więc w tekście sugeruje, że autorzy klas powinni dokonać kompromisu między atomowością, a efektywnym spłaszczaniem obiektów sterty podczas projektowania Value Class, nawet jeśli powodować to będzie docelowo problemy w przypadku wystąpienia Race Condition. Argumentuje, że te ostatnie i tak powinny być unikane, bo ich wyniki nigdy z założenia nie będzie deterministyczny, a ograniczanie Valhalli w celu przygotowanie się na tego typu przypadki brzegowe jest trochę walką z wiatrakami.
Jakie są w tym wnioski dla Was, jako użytkowników końcowych Javy? Wielu nie mam, ale zawsze uważałem, że świadomość tego, jak bardzo skomplikowaną maszynerią jest JVM i ile rzeczy trzeba wziąć pod uwagę przy jej ewolucji buduje empatię – szczególnie jak (podobnie jak ja) należycie do śmieszków, którzy regularnie sobie żartują z ciągłych opóźnień Valhalli.

Źródła
A na koniec, mały bonus. Przy okazji relacji z Keynote KotlinConf (notabene, pojawiły się obiecane nagrania) narzekałem, że przy promocji zupełnie zapomniano o maskotce Kotlina. Myliłem się bardzo – nie tylko słodziak wraca, ale jeszcze dostał imię – od teraz zwie się Kodee!
Jego design przeszedł lekki lifting, dostał też nowych kolorów zgodnych z brandingiem samego Kotlina, ale pozostał jedną z moich ulubionych branżowych maskotek. Nie stracił też nic ze swojej ekspresyjności, za to zyskał sporo nowych „reakcji”. Zobaczcie zresztą sami:

Mam nadzieje, że będzie go w komunikacji około-kotlinowej tylko coraz więcej.
A jak już wrócił temat KotlinConf – stałem się członkiem kapituły Kraków Kotlin User Group, która reaktywuje się po prawie dwóch latach nieobecności. Pierwsze po tej długiej przerwie spotkanie odbędzie się 17 maja, a motywem przewodnim będzie właśnie Keynote KotlinConf. Oglądniemy go sobie razem, aby następnie oddać się przy procentach dyskusji na temat implikacji dla przyszłości języka.

Więc jeśli macie ochotę wpaść do Krakowa, poznać się „w realu” i wypić razem piwo, będzie to świetna ku temu okazja 🤟.

Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


