Czym byłby tydzień bez nowego Projektu w Javie? Dlatego dzisiaj porozmawiamy sobie o Project Babylon. choć nie tylko.

1. Szansa na LINQ (i nie tylko) na JVM – Project Babylon
Miałem już okazję wspominać, jak bardzo doceniam kreatywność w tworzeniu nazw javowych projektów? No to muszę zrobić to jeszcze raz. W zeszłym tygodniu Paul Sandoz, architekt Javy z Oracle, zaproponował rozpoczęcie nowego projektu Javy o nazwie Babylon. Dlaczego tak bardzo podoba mi się ta nazwa? Dowiecie się na końcu akapitu (dla wytrwałych). Ale w międzyczasie…
Pamiętacie, jak w poprzedniej edycji opisywaliśmy, jak trwają pracę umożliwiające Javie możliwości drzemiących w GPU? Jak pamiętacie, wspomniane TornadoVM w tle konwertowało kod Javowy na postać przystępną dla konkretnych architektura hardware. A co by było, gdyby istniał mechanizm pozwalający nie tylko na dostosowanie do instrukcji różnych układów (takich jak GPU czy FPGA), ale również dynamiczne generowanie kodu natywnego dla innych środowisk uruchomieniowych, czy nawet zapytań SQL, podobnie jak to robi obecnie LINQ w C#?
Dla tych, którzy nie mieli nigdy okazji do czynienia z C#, oto przykład użycia LINQ:
DataContext dataContext = new DataContext();
// LINQ Query
var query = from student in dataContext.GetTable<Student>()
where student.FirstName == "Artur"
select student;
// Execute the query and print the results
foreach (var student in query)
{
Console.WriteLine(quot;ID: {student.Id}, First Name: {student.FirstName}, Last Name: {student.LastName}"); } W powyższym kodzie zapytanie LINQ szuka wszystkich studentów o imieniu “Artur” w tabeli Studenci. Kiedy zapytanie jest wykonywane (tj. podczas iteracji przez wynik za pomocą pętli foreach), mechanizm LINQ to SQL tłumaczy zapytanie LINQ na odpowiednie zapytanie SQL, które jest następnie wysyłane do bazy danych.

Babylon ma na celu wprowadzenie możliwości budowania takich mechanizmów, prezentując coś, co nazywa “refleksją kodu”. Aby wytłumaczyć czym jest, wróćmy do podstaw. W językach programowania, takich jak Java, refleksja pozwala programom analizować i modyfikować własne struktury. W Javie refleksja jest obecnie używana do analizy klas, interfejsów, pól i metod w czasie wykonywania bez znajomości ich nazw w czasie kompilacji. To jak zdolność poznania właściwości klasy lub obiektu i manipulowania nimi podczas działania programu.
Jednak “refleksja kodu”, w kontekście Projektu Babylon, ma na celu pójście krok dalej. Zamiast tylko analizować i modyfikować już skompilowane struktury kodu, refleksja kodu ma na celu zapewnienie bardziej szczegółowego i elastycznego dostępu do rzeczywistego kodu źródłowego, niemal jakby program mógł czytać, analizować i zmieniać własne pliki źródłowe.
Oto uproszczony podział tego, jak refleksja kodu działałaby w Projekcie Babylon: Po pierwsze, generowany byłby model programu, polegający na przedstawieniu kodu Javy w strukturalnej formie, przypominającym szczegółowy plan budynku, gdzie ten plan, nazywany “modelem kodu” (jeśli dobrze rozumiem intencje, coś w rodzaju Abstract Syntax Tree), ukazuje strukturę kodu i jego funkcje. Istniejące możliwości refleksji Javy zostałyby zaś rozszerzane, umożliwiając nie tylko przyglądanie się skompilowanym strukturom, ale także dostęp do wspomnianego modelu kodu, zarówno w czasie kompilacji oraz podczas jego wykonywania. Powstać miałyby również API umożliwiające programistom analizowanie modeli kodu, wprowadzanie do niego zmiany, a następnie przekształcać tych modyfikacje z powrotem w kod wykonywalny.
Koncepcja refleksji kodu w Projekcie Babylon dla Javy ma na celu zapewnienie szczegółowego dostępu do oraz manipulacji kodem źródłowym, coś w rodzaju zdolności samomodyfikujących się i introspektywnych. Wyobraźcie sobie programistę Javy piszącego kod przeznaczony dla karty graficznej (GPU). Dzięki refleksji kodu, program Javowy mógłby przyjrzeć się własnemu kodowi, zrozumieć go, a następnie przekształcić się, aby był zoptymalizowany dla GPU, wszystko bez konieczności ręcznej transformacji przez programistę. Chodzi o to, aby dać Javie zdolność dostosowywania się w zależności od tego, gdzie i jak jest używana.
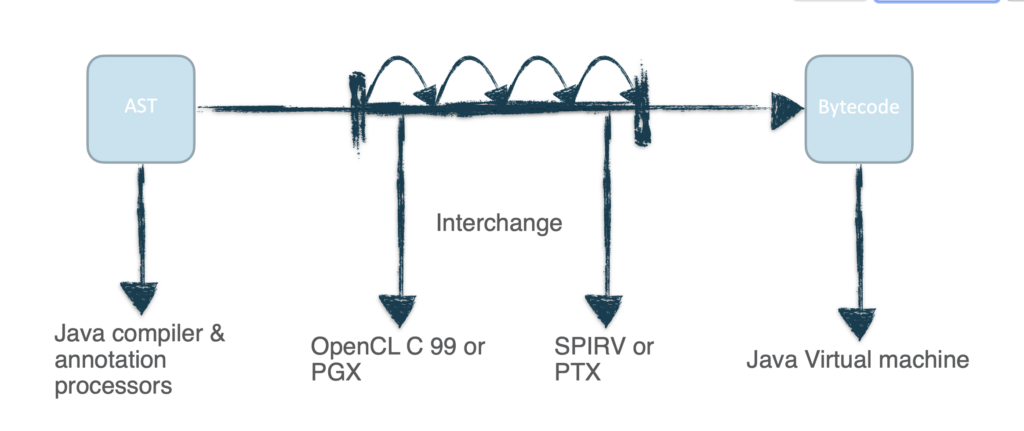
Dla porównania, inne języki JVM, takie jak Kotlin, Scala i Clojure, już mają funkcje pozwalające na metaprogramowania lub system makr, które ułatwiają “introspekcję” i transformację kodu. Jednak podejście Babylon do refleksji kodu, ma na celu dostarczenie standardowego mechanizmu i doprowadzenie zdolności refleksyjnych Javy do poziomu, albo nawet wyżej, innych języków JVM-owych. Jeżeli temat Was zaciekawił, zapraszam do prezentacji wideo z JVMLS o Code Reflection znajdziecie tutaj:
Jak obiecałem, na koniec ciekawostka nazewnicza: “Babel” i “Babylon” mają swoje korzenie w biblijnej historii Wieży Babel w Księdze Rodzaju. Jak prawdopodobnie wszyscy wiedzą, w tej opowieści ludzie, mówiący jednym językiem, próbowali zbudować wieżę w mieście Babel, aby dotrzeć do niebios. W wyniku ich ambicji Bóg skonfundował ich mowę, prowadząc do wielu języków i rozproszenia ludzkości po Ziemi. Projekt Babylon, w pewnym sensie, próbuje zrobić odwrotnie: łączyć różne “języki” programowania czy modele, czyniąc je bardziej jednolitymi pod parasolem Javy.
Jednak to nie koniec. Angielskie słowa “Babel” i “Babylon” pochodzą od hebrajskiego “Bāḇel” (בָּבֶל), które jest związane z starożytnym miastem Babilon, ważnym miastem Mezopotamii znane z jego kulturowego i historycznego znaczenia. Historycznie, miasto Babilon było miejscem spotkań różnych kultur, języków i wiedzy w starożytnej Mezopotamii. Podobnie, Projekt Babylon ma na celu połączenie różnych modeli programowania, czyniąc Javę bardziej wszechstronną i powiązaną z różnorodnymi paradygmatami.
Albo ja sobie za dużo dopowiadam 🤷.
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!



2. Jeszcze jeden sposób na optymalizacje Zimnego Startu w Javie – Azul Platform Prime
Zastanawiałem się, czy w ogóle zawrzeć tą informacje w nowej edycji, bo mówimy jednak o rozwiązaniu bardzo specyficznym dla platformy Azul, ale całość na tyle fajnie wpisuje mi się w obraz szeroko rozumianej chmurowej Javy, że zdecydowałem się opowiedzieć Wam nieco o niedawno zapowiedzianej Azul Platform Prime.

Także do rzeczy: JVM rozpoczyna każdą sesję z de facto czystą kartą, bez pamięci o swoich poprzednich działaniach. Ten sposób działania prowadzi do tego, że każdorazowo do osiągnięcia szczytowej wydajności niezbędny jest początkowy jej “rozruch”, w czasie którego może dochodzić dotakich problemów jak wydłużony czas uruchamiania wpływający na responsywność aplikacji, zauważalne skoki obciążenia CPU podczas optymalizacji JIT czy dziwne skoki latencji. Aby zaradzić tym problemom, deweloperzy często sięgali po obejścia takie jak ręczne “rozgrzewanie” aplikacji przed wpuszczeniem jej do ruchu. Rozwiązania te zwiększają jednak złożoność operacyjną i koszty.
Azul postanowił przyjrzeć się tematowi, i zaproponował Azul Platform Prime zintegrowaną z technologią ReadyNow. ReadyNow zbiera dane profilowania z sesji JVM, co pozwala następnym uruchomieniom pominąć długą fazę profilowania i od razu rozpocząć kompilację – trochę jak PGO z GraalVM czy profilowanie zaproponowane przez twórców Project Loom. W mojej głowie całość przypomina też nieco CRaC, tylko zatrzymuje się jakby krok wcześniej – zamiast “zrzucać” na dysk cały skompilowany przez JIT kod, projekt archiwizuje “wkład” do procesu kompilacji.
No i tyle, wydaje mi się to być dość interesujący klocek w całym ekosystmie, dlatego postanowiłem poświęcić mu tą sekcje. Dodatkowo, jeżeli myśleliście, że to ja robię naciągane popkulturowe porównania, to Azulowi udało się w zapowiedzi przemycić nawiązanie do “Memento” Nolana. Szanuje – mój drugi ulubiony film reżysera, zaraz po Interstellar.

3. Release Radar
Micronaut 4.1.0
Fundacja Micronaut wydała Micronaut 4.1.0. Jedną z najważniejszych nowych funkcji są Mappery Beanów oanotowanych jako @Introspected, które ułatwiają automatyczne mapowanie między różnymi typami, w oparciu o wprowadzony w wersji 4.0 Expression Language działający w czasie kompilacji, bez korzystania z refleksji i zapewniający bezpieczeństwo typów. Framework wprowadza również IntrospectionBuilder – Budowniczego Introspekcji (drugi raz dzisiaj używam tego słowa) do dynamicznego generowania konstruktorów dla określonych typów przy użyciu adnotacji @Introspected.
Znacząco poprawiono również wsparcie dla KSP (Kotlin Symbol Processing API), kierując się do osób tworzących aplikacje Micronaut z użyciem tego następcy annotation procesora promowanego jako wiodącą przez nowe wersje Kotlina. Ponadto moduły takie jak Micronaut Data, Micronaut Serialization i Micronaut Kafka otrzymały nowe wersje zaktualizowane, przy czym ten ostatni wprowadza ważne ulepszenia dotyczące offsetów Kafki. Micronaut OpenAPI kontynuuje doskonalenie generowania dokumentacji OpenAPI w czasie kompilacji, a Micronaut RabbitMQ wprowadza funkcje związane z flagą “mandatory” AMQP i zdarzeniami konsumenta RabbitMQ
Jednakże lista nowości nie kończy się na tym. Micronaut Security teraz oferuje lepsze możliwości debugowania, zwłaszcza podczas niepowodzeń logowania. Zauważalna zmiana nastąpiła w integracji z Neo4j, która dokonała migracji na Testcontainers Neo4j i usunięciem zależności na EmbeddedNeo4jServer.
Hibernate 6.3
Najnowsza wersja Hibernate ORM, oznaczona numerem 6.3.0, dostosowuje framework o standardu Jakarta Persistence 3.2. Jest to widoczne we wsparciu dla literałów numerycznych (jak 123L symbolizujący long) w zapytaniach HQL/JPQL. Wersja ta wprowadza również standaryzację składni dla BigInteger i BigDecimal.
Możliwości zapytań w Hibernate również doczekały się udoskonaleń. Jedną z nowych funkcji jest generowanie metod w stylu DAO dla Named Queries jako część generatora statycznego metamodelu JPA, co ułatwia ich użycie.
List<Book> books =
Book_.findByTitleAndType(entityManager, titlePattern, Type.BOOK);
Wprowadzono także metody wyszukiwania, gdzie nowa adnotacja @Find pozwala na przetwarzanie dowolnych metod przez generator, tworząc metody podobne do metod zapytań. Wsparcie dynamicznego fetchowania do zapytań SUBSELECT wprowadza zaś bardziej elastyczny styl pobierania, pozwalając programistom definiować profile kontrolujące, jakie powiązania są ładowane w czasie wykonywania.
@FetchProfile(name = "EagerBook")
@FetchProfile(name = "EagerBookWithSubselect")
@Entity
class Book {
@FetchProfileOverride(profile = Book_.EAGER_BOOK_WITH_SUBSELECT, mode = SUBSELECT)
Set<Author> authors;
}
Session session = ...;
session.enableFetchProfile( Book_.EAGER_BOOK_WITH_SUBSELECT);
Istotnym dodatkiem w tej wersji jest zdolność tworzenia kryteriów z poziomu HQL, a nowa klasa CriteriaDefinition upraszcza pracę z takowymi. Wprowadzenie metody StatelessSession.upsert() ułatwia zaś wykonywanie operacji typu SQL UPSERT/MERGE z użyciem StatelessSession.
Dla adopcji nowej wersji Hibernate ważne też będzie wydanie wraz z premierą nowej wersji dwóch nowych przewodników: jeden z nich oferuje wprowadzenie do Hibernate 6, a drugi zagłębia się w składnię Hibernate Query Language.
Quarkus 3.3.0
Quarkus ogłosił swoją najnowszą wersję, Quarkus 3.3.0. To wydanie wprowadza wiele usprawnień, w tym OpenTelemetry w wersji 1.28, rozszerzenie Pulsar w Reactive Messaging, różne ulepszenia związane z bezpieczeństwem, zwłaszcza w OIDC, oraz przesiadkę z przestarzałego rozszerzenia Elasticsearch high-level-rest-client na nowsze rozszerzenie Elasticsearch Java Client. Co więcej, programiści korzystający z REST Client Reactive mogą teraz dostosowywać ObjectMapper podczas używania REST Client Reactive Jackson. Najnowsza iteracja Micrometer pozwala na dostosowanie MeterRegistry i wprowadza metryki dla Netty’ego.
Istotną zmiana nastąpiła zaś w kwestii definiowania GraalVM. Quarkus dokonał zmiany w zależnościach, przechodząc z nieoficjalnego artefaktu svm do oficjalnego SDK GraalVM o nazwie org.graalvm.sdk:graal-sdk. Zależności tego artefaktu w Quarkus są oznaczone jako provided, co oznacza, że nie są one automatycznie dołączane do projektu. Na szczęście org.graalvm.sdk:graal-sdk jest częścią BOM Quarkus, więc nie musisz określać jego wersji podczas dodawania do projektu, ale jeśli potrzebujesz korzystać z podstawień (substitutions) GraalVM w swoich aplikacjach, musisz ręcznie dodać odpowiednią zależność.
Dla ambitnych: Czym są podstawienia w GraalVM?
Podstawienia to mechanizmu, który pozwala programistom zastępować lub modyfikować klasy, metody lub pola podczas procesu generowania obrazu natywnego. Jest to sposób na obejście problemów lub optymalizację kodu podczas konwersji aplikacji Java na natywne pliki wykonywalne za pomocą narzędzia Native Image w GraalVM. Dzięki podstawieniom, bez modyfikowania oryginalnego kodu źródłowego lub oczekiwania na zmiany od twórców bibliotek, programiści mogą określić, że podczas budowy obrazu natywnego pewna klasa, metoda lub pole powinny zostać zastąpione alternatywną implementacją, dostosowaną do środowiska natywnego.
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!
Bonus: What is the future of Java in today’s enterprise?
Ok, a na koniec jeszcze nieco prywaty.

Ostatnimi czasy miałem okazję objąć rolę Head of Java/Kotlin Development w VirtusLab (firmy stojącej min. za kompilatorem Scali), co daje mi dość unikalną możliwość promowania nowości javowych – wszystkich featurów o których regularnie pisze – wśród biznesu i patrzenia, jak realnie znajdują produkcyjne użycie. Dlatego też w zeszłym tygodniu opublikowałem tekst What is the future of Java in today’s enterprise?, w którym starałem się wyjaśnić szeroko rozumianemu “biznesowi” na co przekłada się ostatnie modernizacje języka, JVM i ekosystemu. Z pierwszego feedbacku wyszło fajnie, zdecydowałem się więc na #selfplug.
Jeżeli więc szukacie sposobu na przemycenie choć trochę z wiedzy z tego newslettera do osób decyzyjnych, polecam tą publikacje 😃
PS: W nagrodę dla tych co dotrwali – tekst z mema z Gru to “The workers speak new languages” po starogrecku 😃
PS2: Nie musicie dziękować 😃
Discover more great content!
- Save time and effort
- Read handpicked articles
- Free yourself from spam

