Firstly, I’d like to apologize for the recent inconsistency in my posts, which was a result of my vacation aligning with a public holiday in Poland. Starting next week, I aim to resume the regular Tuesday publishing schedule.

1. JDK 21 Release Candidate has been released
This is going to be fairly brief, but it’s information I didn’t want to let go of – for there has appeared the first Release Candidate of JDK 21, the version that masses of people are sharpening their teeth for. I’m definitely not going to try to break down Autumn Java now into the various features that come with it (I’ve already done that with the Rampdown phase, and it will probably come with the release of the Stable version as well). While I will leave Thomas Schatzel’s publication on Garbage Collectors for the aforementioned final release, I will share some rather promising figures.
For those who take pleasure in benchmarking, there’s some positive news regarding the Panama project. Alexander Zakusylo conducted a performance comparison of several native query solutions in the ecosystem back in 2019. He scrutinized seven different methods including JNI, BridJ, and Panama. A comprehensive explanation of each is available in the original text. Four years ago, Panama was significantly slower than the leading solutions. However, it’s 2023 now, and it’s evident that the successive preview versions have made progress. Alexander decided to conduct the tests again, this time using the latest version from JDK 21. As a result, Panama has now topped the rankings. The JDK Foreign Function/Memory API Preview (JEP-424) operates about twice as fast as JNI.
Of course, this represents just one benchmark (and we can likely anticipate a surge of others shortly), but it effectively highlights the performance improvement in the project.

Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!



2. Pi4J Operating System for Java development on Raspberry Pi
For some time, it appeared that the era of the Raspberry Pi being a cost-effective, inexpensive computer might have ended. However, recent trends suggest that prices are gradually decreasing, at least in Poland. Despite no new versions since 2019, it remains a remarkably potent device. In my home, it functions as a network infrastructure controller, VPN, Plex server, and Home Assistants… all at once.
It’s not surprising that it functions effectively as a computer for learning programming.
The Raspberry Pi operating system (OS) is specifically designed for JVM developers via the Pi4J initiative. The Pi4J project originated from Pascal Mathis, a student at FHNW University in Switzerland, who started it to control the I/O elements of the Raspberry Pi (like GPIO, SPI, I2C, SERIAL) using Java. Dieter Holz, a lecturer at FHNW, expanded this initiative by creating various versions of the OS to give his students the optimal working environment. The concept was to allow learners to concentrate on programming without the need to worry about Linux configurations and associated tools.
Instead of being a completely new operating system, Pi4J OS is a derivative of the official Raspberry Pi operating system, incorporating the Pi4J project. This implies that it includes extra tools and configurations specifically designed for Java and JavaFX developers. From the moment of installation, it provides everything a novice developer requires. Moreover, Pi4J simplifies the use of Raspberry Pi components, making it perfect for those who wish to explore this ecosystem.
Frank Delaport of Azula is actively involved in this project and presents in a series of articles on foojay.io on how to use various JDK ecosystem tools (such as SDKMan and Kotlin) on the Raspberry Pi. His presentation “Update on #JavaOnRaspberryPi and Pi4J” provides an excellent introduction for those who have an unused microcomputer lying in a drawer and want to revive it.
3. Release Radar
Liberica JDK Performance Edition
We’re kicking off with a rather unique project. BellSoft, a firm I’ve discussed several times in the past, has launched the Liberica JDK Performance Edition. This is essentially JDK 11, enhanced by incorporating VM performance improvements from JDK 17. This approach allows users to experience performance boosts of up to 10-15%, without the need for substantial code modifications. As you might easily infer, this solution is specifically targeted at businesses utilizing JDK 11, who may be hesitant or unable to upgrade to newer versions. The backported improvements include, among other things, fixes to Garbage Collectors and improved support for NUMA (Non-Uniform Memory Access).
Starting from August 1, this edition is accessible to existing Liberica JDK subscribers without any additional cost, and it comes along with other tools from BellSoft. I’m curious to see if there will be more such offerings in the future. The main concern appears to be addressing the question that currently fascinates me the most – which projects are opting for JDK with backported VM features instead of a direct transition to JDK 17? If you have any experience with this, I would be delighted to hear your stories.
Fury
Now we’re delving into a topic I’m always somewhat cautious about – serialisation. I’ve previously mocked a new library on this topic, so I scrutinize every solution extremely carefully. Because, how can one not be skeptical when they see this:
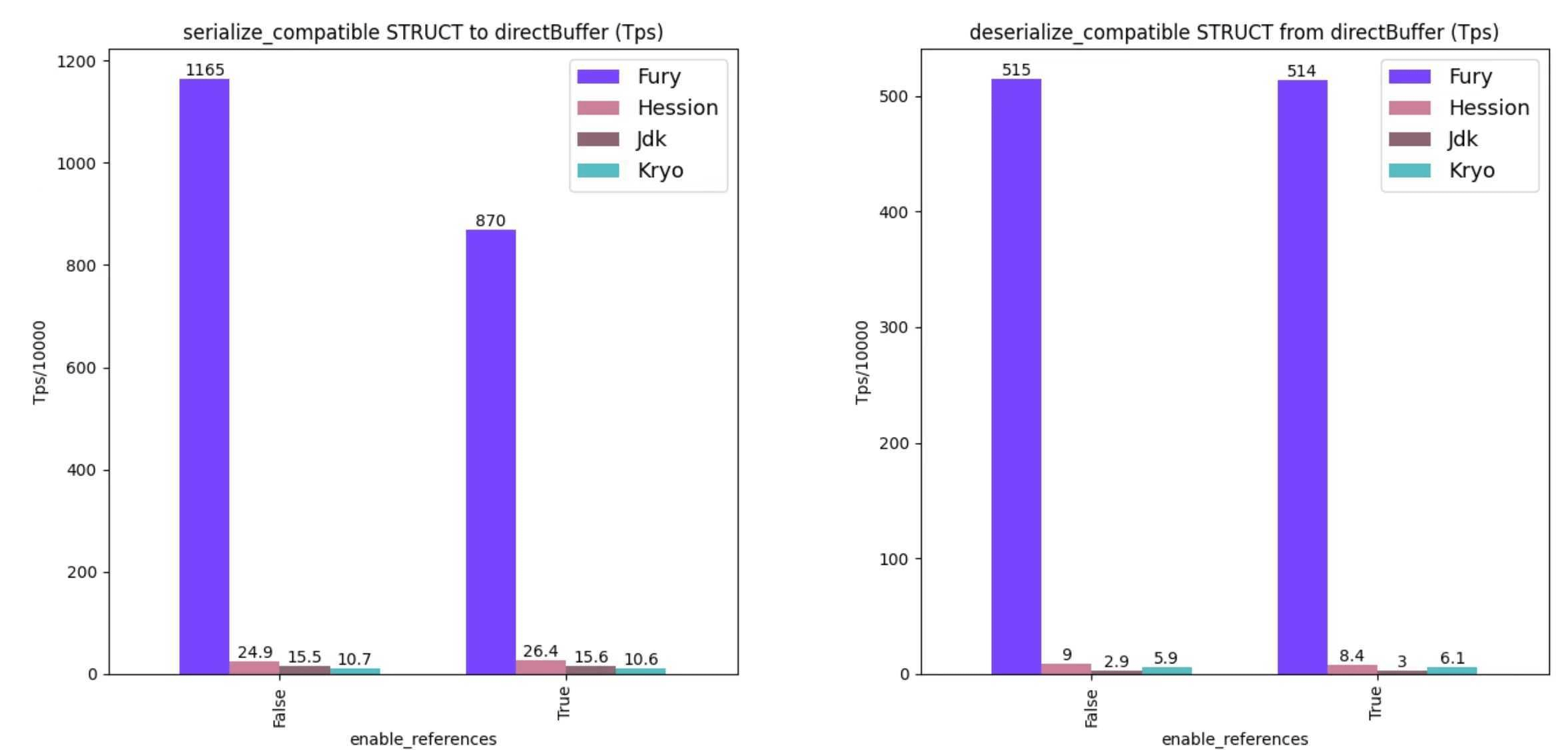
It appears that the Fury, developed by Ant Group, is a highly credible solution. The developers have taken the time to detail why they chose specific benchmarks over others in an insightful blog post: Fury – A blazing fast multi-language serialization framework powered by jit and zero-copy. Now, I will attempt to explain this to you, which necessitated some doctoring on my part. 😄

The two fundamental serialization methods are static and dynamic. Frameworks that utilize static serialization, like protobuf, operate on a pre-established schema. Serialization is executed based on this schema, necessitating that both the sender and receiver have prior knowledge of it. This method ensures speed and efficiency. However, it does have its drawbacks, primarily due to a lack of flexibility – communication between different programming languages based on a static data structure can be challenging, particularly when schema evolution is necessary. On the other hand, dynamic serialization frameworks, such as Serialisable in JDK, Kryo or Hessian, are not reliant on a fixed schema. They define the data structure at runtime, making them more adaptable. This results in a better user experience and the ability to use polymorphism. Unfortunately, this flexibility often comes with decreased performance, which can pose a problem in scenarios where high throughput is required, like bulk data transfer.
Fury aims to strike a balance between two worlds, merging the benefits of both: the adaptability of dynamic serialisation and the efficiency of static serialisation. The framework is built to ensure complete compatibility with existing Java solutions, while also providing versions for other platforms. Fury employs a range of sophisticated serialisation methods, along with support for SIMD operations. The solution also utilises Zero-Copy, a data transfer technique that avoids physical copying of data between memory buffers or other system layers, thereby reducing latency during data transfers by eliminating unnecessary memory copies. Furthermore, Fury incorporates a JIT compiler that uses real-time object type data to generate optimised serialisation code. The framework also prioritises efficient cache usage, maximising data and CPU instruction cache hits, and accommodates multiple serialisation protocols, adapting to various application needs.

If an individual is not content with the explanation I’ve put together, they are, naturally, invited to view the original publication. The most crucial question remains – who is conducting tests in production?
Eclipse JNoSQL 1.0.0
We are now venturing into Jakarta EE territory. This is due to the fact that I overlooked the launch of JNoSQL 1.0.0, but I will take advantage of the release of version 1.0.1 (and the publication of an article on DZone) to familiarize you with this project.
Eclipse JNoSQL is a Java library implementing the Jakarta NoSQL and Jakarta Data specifications, aiming to simplify the integration of Java applications with NoSQL databases. The framework is anticipated to provide features like integration with Contexts and CDI, and the capability to create Java-based Query or patterns familiar in the enterprise Java world such as Repositories and Template. Moreover, it introduces annotations similar to those of JPA, like @Column or @Entity. These annotations make the mapping of Java objects to over twenty NoSQL databases easier – you can find the list here.
Eclipse JNoSQL 1.0.0 has brought in several upgrades to enhance the framework’s abilities and the integration procedure between Java and NoSQL databases. The latest version provides a more straightforward database configuration, lessening the initial setup work. It now also supports Java Records, and their smooth mapping to NoSQL data structures.
I must confess that it feels quite odd when I use a generic NoSQL framework, even though I occasionally use Spring Data for that purpose. It gives me the strange gut feeling that I could just as easily be utilizing basic PostgreSQL underneath.
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!
Jlama & llama2.java
Finally, we have two projects that are similar in nature, but there is a certain logic in it.
2023 continues to be dominated by the topic of Large Language Models, with new initiatives in this field popping up almost constantly. One of the most notable is the LLaMA developed by Meta, a rival to OpenAI’s GPT. Meta recently introduced LLaMA 2, an enhanced version of its model. The crucial detail for this article is that this model is open source and licensed for commercial use, unlike its predecessor which was solely for research purposes. This has sparked an industry competition that has extended into the Java realm. Two projects are particularly prominent in this race: Jlama and llama2.java.
Jlama is a Java-based processing engine for LLM, compatible with models like Llama, Llama2, and GPT-2 (which has also been released), as well as the Huggingface SafeTensors model format. It requires Java 20 and utilizes the Vector API, frequently discussed here, which facilitates the rapid vector calculations necessary for inferring from models. Currently, this is the primary information about it, but it’s important to mention that it is released under the Apache license.
Every edition brings us news about Java solutions in the field of artificial intelligence, which fills me with enthusiasm. These projects reinforce my belief: the latest features of the language pave the way for more applications, and their influence extends beyond just simple syntax enhancements. Due to the swift progress in recent years and projects of this nature, Java is proving that it is leading the pack of tools used in modern solutions, effectively quieting its critics who predict its impending demise.

With that hopeful remark, I bid you farewell – we’ll meet again next week (I’m already planning in the usual Tuesday manner)!
Discover more great content!
- Save time and effort
- Read handpicked articles
- Free yourself from spam

