Today we have a worthy edition, containing an overview of serialization libraries (along with a new player), the effect of the Lilliput project, and a release radar stuffed to the brim.

1. Loial – a new player among serialization libraries
It is often said that benchmarks are among the most deceptive publications. This is because they often have a certain agenda behind them (who didn’t stretch lab results in college?), and due to the number of moving parts that need to be taken into account when creating one, even doing a test in good faith can distort reality. That’s why I usually don’t focus on benchmarks here…

Today, however, I’m going to break that rule, because in recent weeks I’ve found my new gold standard when it comes to how performance test results should be shared with the community.
Indeed, Nicholas Vaidyanathan, an engineer working at AWS, has prepared a thorough comparison of available serialization libraries. This in itself would be interesting material, but what is particularly eye-catching is how much emphasis he placed on defining and motivating the methodology. In fact, a whole separate text is devoted to them, where he, with almost academic precision, defines the individual test cases and the particular parameters that are of interest from his perspective. I won’t dwell on the results here, because there are no obvious winners (as is usually the case in life), so I refer those interested to the results.
Oh, and apropos of hidden agendas – lest it be said that these benchmarks were created so completely gratuitously. The whole research that the author made (and he also prepared a review of the solutions used by the various libraries he tested) happened because he decided to present his own library, Loial, which he based on the experiences he gained working at Amazon (also thoroughly described by him). Loial has been subjected to similarly thorough testing, and the results are more than surprising – as he managed with his solution to achieve surprisingly good results in basically all the metrics indicated.

One can, of course, argue the results presented by Nico, try to replicate them and even suggest other test cases. However, thanks to the cross-sectional approach he took to describing his method, we have at least this possibility. So, s a whole, the above set of publications continues to be a “gold standard” in my eyes, especially if a goal is to enable reproducibility of results and start some data-driven discussion – as singular benchmarks will not cover all possible cases for us.
Have a look at the sources – as a series, the texts below are probably the best overview of how the world of serialization libraries looks in mid-2023.
Sources
- Best Practice Performance Comparison for Java Serialization libraries
- Results of JMH Performance Comparison for Java Serialization libraries
- Mapping the Serialization Territory
- Motivating a new Serialization API
- Loial: fastest, leanest, highest quality Java object serialization
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!



2. JEP 450: The child of Project Lilliput
Well, we’re back to the topic of JEPs. However, while I don’t want to talk again about more candidates coming to JDK 21 – we’ll summarize that collectively when the changelist will become “frozen” – one really interesting JEP has emerged: JEP 450: Compact Object Headers (Experimental), a child of the Lilliput project.
As a reminder, Lilliput’s goal is to reduce the size of Java object headers in the Hotspot JVM from 128 bits to 64 bits. At the moment each object, whether small or large, has a fixed overhead of 128 bits in theory, and 96 bits in practice (with header compression enabled). 128-bit does not seem like a large memory overhead, however, it should be remembered that we are talking about the header that is added to every single object. In many applications, e.g., when many tiny ones are created (the developers cite, for example, machine learning), this overhead becomes very significant, hence the work on Lilliput.
So let’s take a look at what JEP 450 brings. In general, the reduction in the size of the header has been achieved by carefully redesigning of its structure. Additionally the necessary improvements in the core functions of the JVM to support a compact header format needed to be made. In the current model, the object header consists of two parts: the mark word and the class word. The mark word contains information about Garbage Collector process or hashcode. The class word follows the mark word and contains information about the class pointer. The new compact header format combines mark word and class word by reducing the size of the hashcode and moving the class pointer to the mark word, essentially reducing header overhead.
But what is perhaps most interesting is the very sizable risk section, wider than ever. But no surprises there – as we are talking about digging into the “guts” of the JVM itself. In the aforementioned list we find, for example
- limiting the space that could be useful for further language development
- potential errors in legacy code
- possible introduction of performance problems due to required refactorings
- limitations of compressed class pointers
and more.
At the same time, the developers are not giving up, because the potential reward is sizable – according to the first tests, we are talking about up to 20% percent reduction in memory usage, and this is a high risk, high reward game.
If the above changes have piqued your interest, as usual, for more details I refer you to the original JEP, but also to the Java Newscast video, which details each change:
Sources
- JEP 450: Compact Object Headers (Experimental)
- Save 10-20% Memory With Compact Headers – Inside Java Newscast #48
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!
3. Release Radar
It’s been a long time since the radar release and we’ve accumulated news. And very well – because each of the novelties presented today is at worst an interesting curiosity, and potentially very useful.
Azul Zulu JDK 17 with CRaC support
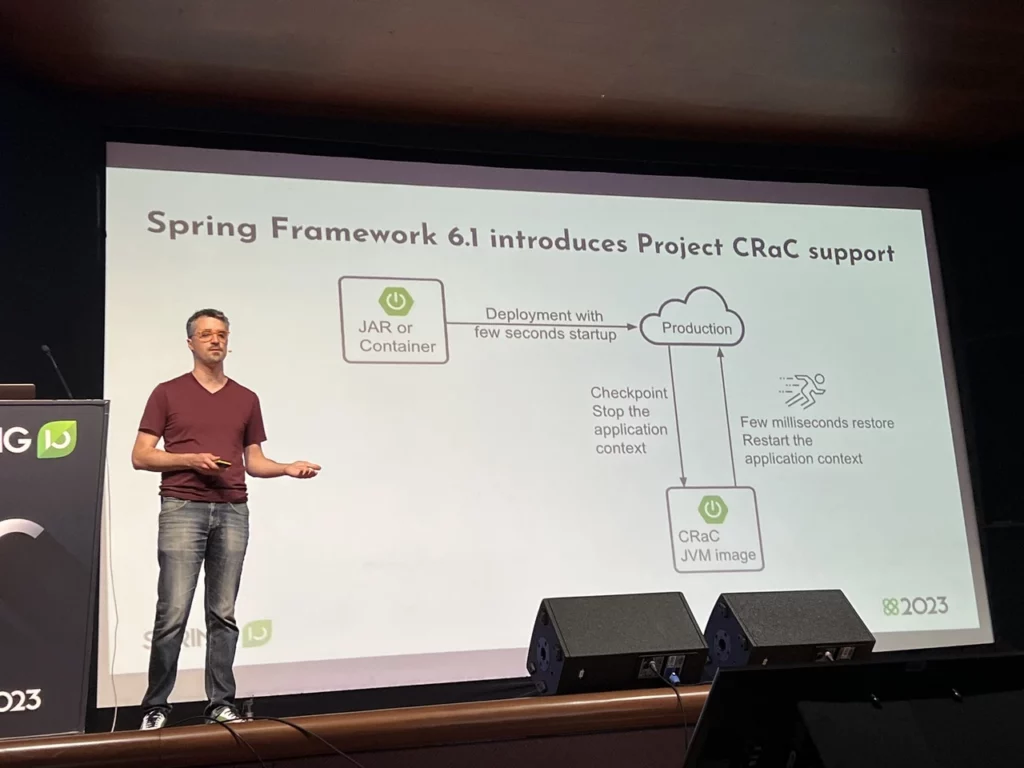
The first release will leave us in the JDK world. That’s because Azul has announced the release of its OpenJDK 17 – Zulu – which includes built-in support for the CRaC API.
Okay, a lot, but let’s remind what is this CRaC? The CRaC API helps coordinate JDK and application resources with the checkpoint/restore Checkpoint/Restore in Userspace (CRIU) mechanism. It allows you to create a “checkpoint” – or the aforementioned memory dump – at any point in the application’s operation as defined by the software developer. It allows Java applications to avoid a long startup and “warm-up” process by saving the full state of the runtime environment.
Do I have any retro gamers among my readers? If so, the whole thing works in a similar way to the Save State functionality in emulators. In modern games you have “classic” saving – we select those fragments that will allow us to recreate the state of the application later, and only save them. Save State does not play with such finesse – as computers have moved forward and we have more disk space, we simply dump the entire memory state to disk and then recreate 1:1 for ourselves when needed.

Of course, CRaC has limitations (after all, the runtime environment itself can change, plus randomization is difficult). However, the whole thing is already being driven by, for example, Amazon Lambda SnapStart, and individual frameworks are boasting about their experiments with the tool, the use of which is said to yield really good results:
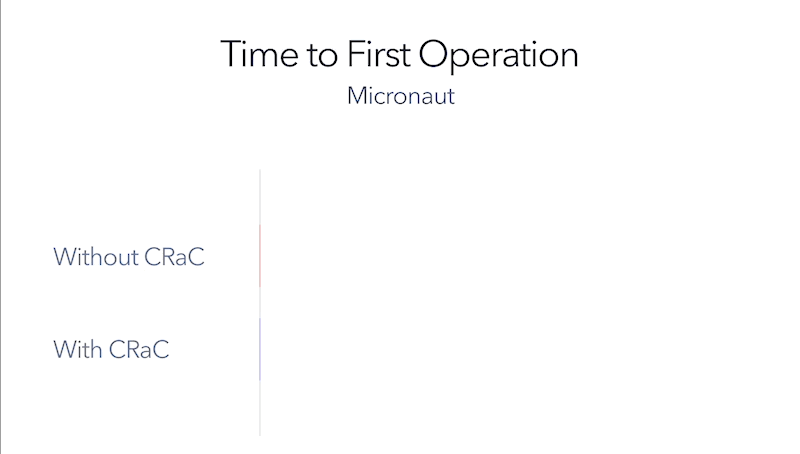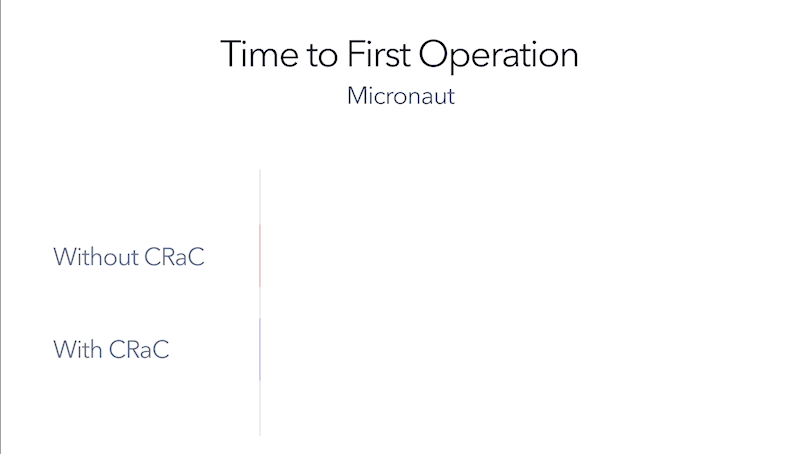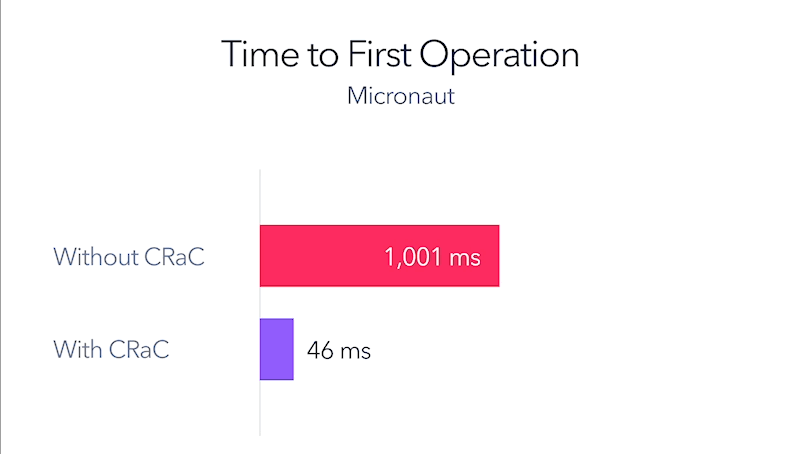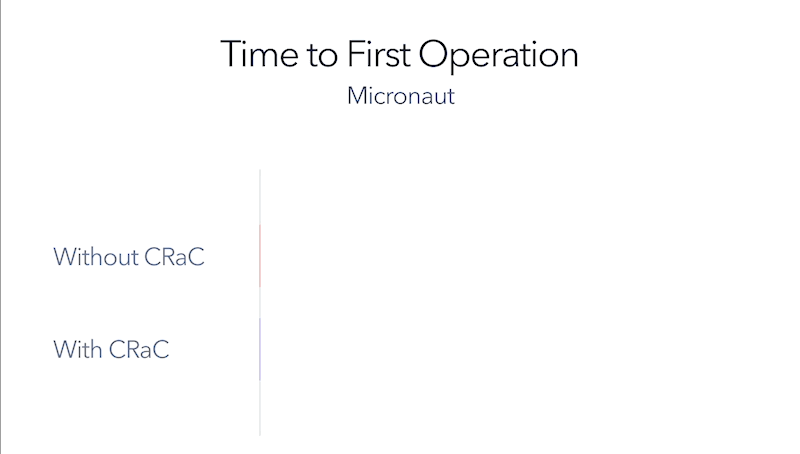
From the very beginning, Anton Kozlov of Azul was behind the project, also the appearance of the release should not surprise anyone. To my knowledge, however, Azul is the first vendor to provide commercial support for the technology.
MicroStream 8.0
MicroStream is an in-memory persistence system for object graphs, allowing them to be efficiently stored, loaded, queried. It is designed to minimize the need for object-relational mapping (ORM), which gives its creator considerable advantages when it comes to the solution’s performance, as well as simplifying the data model. In addition, the whole thing comes in the form of a library, so you can easily add it to your existing project.
MicroStream v8.0 introduces support for Lazy Collections, such as LazyArrayList, LazyHashSet and LazyHashMap, that can load data into memory when it is needed, with only a slight increase in access time. In addition, data can be easily cleaned by Garbage Collector when memory usage is high, making it a very good option for application cache implementations. The Lazy Collections are stored in segments, and the user can control the number of elements in each of these, although the developers rather encourage the use of their defaults.
JavaMelody 2.0
JavaMelody is a performance monitoring and profiling tool designed primarily for Java EE applications. It is a rather obscure project, but I have a special place in my heart for it – in my first job with Java EE, the first task I had was just to integrate it into a project using the Extensions mechanism.
I’ll admit that I haven’t heard much about it since then, so it came as quite a surprise to me when release of version 2.0 was announced. As you can easily guess, the increase in numbering is related to the transition to Jakarte EE 10 and the new jakarta.* package (I think you’re already familiar with this pattern, we’ve covered it many times before). For this reason, by the way, JavaMelody 2.0 only supports Spring Boot 3+ – if one wants to stay on an earlier version of Spring, one must stay on JavaMelody from the 1.9.x branch.

kotlinx.coroutines 1.7.0
At the very end, I left Kotlin. This is because a new version of Corutines has recently appeared. This is because not everyone may realize that although Corutines are a part of Kotlin, its release cycle remains independent of the language itself. Although we have long enjoyed Kotlin version 1.8, we recently got our hands on kotlinx.coroutines 1.7.0. What does it bring?
The most interesting change is the new implementation of the Channel API. Its new data structure is intended to fix problems with the previous implementation, as it had issues with correctness, maintainability, and performance. The new implementation uses array-based data structures and more efficient algorithms for fetching and adding elements. The new Channels implementation results in much faster performance both in sequential use and in parallelized cases. The change is technical in nature and does not affect users. The whole algorithm is novel enough to live up to be published as academic paper: Fast and Scalable Channels in Kotlin Coroutines.

Of other interesting additions, we also got an improvement in the Mutex mechanism, upgrades in kotlinx-coroutines-test (especially in terms of better timeout support), and Kotlin/Native got support for Dispatchers.IO.
PS: These are the kind of emails I like to get ❤️. There are many of us!. Thank you for being here!.
Discover more great content!
- Save time and effort
- Read handpicked articles
- Free yourself from spam

