Dzisiaj mamy edycję „na bogato” – przegląd bibliotek do serializacji (wraz z nowym graczem), efekt projektu Liliput, a także wypchany po brzegi release radar.

1. Stan bibliotek do serializacji obiektów w Javie w Q2 2023 r
Często powtarza się, że benchmarki są jednymi z najbardziej zwodniczych publikacji. Niejednokrotnie mają bowiem za sobą pewną agendę (kto na studiach nie naciągał wyników laborek?), a ze względu na ilość elementów ruchomych, które trzeba wziąć pod uwagę przy tworzeniu takowego, nawet robiąc test w dobrej wierze można zakłamać rzeczywistość. Dlatego też zwykle nie skupiam się tutaj na benchmarkach…

Dzisiaj jednak złamię tą zasadę, bo w ostatnich tygodniach odnalazłem mój nowy standard złota jeśli chodzi o to, jak wynikami testów wydajnościowych powinno się dzielić ze społecznością.
Nicholas Vaidyanathan, inżynier pracujący w AWS, przygotował bowiem gruntowne porównanie dostępnych bibliotek do serializacji. Już samo w sobie to byłoby interesującym materiałem, ale to, co szczególnie przykuwa uwagę to fakt, jak dużo nacisku położył on na zdefiniowanie i umotywowanie poszczególnych przypadków testowych. Poświęcony został im bowiem cały osobny tekst, gdzie z akademicką wręcz precyzją definiuje poszczególne przypadki testowe i poszczególne parametry, które są z jego perspektywy interesujące. Nad wynikami nie będę się tutaj rozwodził, bo nie ma oczywistych zwycięzców (jak to zwykle w życiu bywa), więc zainteresowanych odsyłam do wyników wyników
A, i apropo ukrytych agend – żeby nie było, że te benchmarki powstały tak zupełnie bezinteresownie. Cały resorach którego dokonał autor (a przygotował też on przegląd rozwiązań używanych przez poszczególne testowane przez niego biblioteki) wydarzył się, bowiem postanowił zaprezentować swoją własną bibliotekę, Loial, którą oparł o swoich doświadczeniach, które nabrał pracując w Amazonie (również gruntownie przez niego opisanych). Loial został poddany podobnie gruntownym testom, i wyniki są więcej niż zaskakujące – udało mu się bowiem swoim rozwiązaniem osiągnąć zaskakująco dobre wyniki w zasadzie wszystkich wskazanych metrykach. Ta jednak jest rozwiązaniem dość dziwnym – de fakto wymaga masy manualnej pracy, przez co nie dziwią jej niezwykle dobre wyniki, dlatego ciężko ją porównać do reszty rozwiązań. Ciekawą dyskusje znajdziecie tutaj.

Można więc oczywiście dyskutować nad zaprezentowanymi przez Nico wynikami, próbować je powtórzyć i choćby zaproponować inne przypadki testowe. Dzięki jednak temu, jak przekrojowo podszedł on do opisania swojej metody, mamy przynajmniej taką możliwość. Całościowo, powyższy zestaw publikacji to dalej w moich oczach wzór, jeżeli chcemy móc zapewnić reprodukowalność wyników i rozpocząć jakąś data-driven dyskusję. A że benchmarki nie pokryją nam wszystkich możliwych przypadków, to już raczej truizm.
Rzućcie sobie okiem na źródła – w komplecie poniższe teksty stanowią chyba najlepszy przegląd tego, jak w połowie 2023 prezentuje się świat bibliotek do serializacji.
Źródła
- Best Practice Performance Comparison for Java Serialization libraries
- Results of JMH Performance Comparison for Java Serialization libraries
- Mapping the Serialization Territory
- Motivating a new Serialization API
- Loial: fastest, leanest, highest quality Java object serialization
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. JEP 450: Dziecko Projektu Liliput
No, i wracamy do tematu JEP-ów. O ile jednak nie chce mi się ponownie opowiadać o kolejnych kandydatach trafiających do JDK 21 – podsumujemy sobie to zbiorczo przy okazji „zamrożenia” wydania – to jednak pojawił się jeden naprawdę ciekawy. Mowa tutaj bowiem o JEP 450: Compact Object Headers (Experimental), dziecku projektu Liliput.
Dla przypomnienia: celem Liliputa jest zmniejszenie rozmiaru nagłówków obiektów Java w maszynie JVM Hotspot ze 128 bitów do 64 bitów lub mniej. W tej chwili bowiem każdy obiekt, niezależnie czy mały, czy duży, posiada stały narzut w teorii 128-bitów, a w praktyce (przy włączonej kompresji nagłówków) 96-bitów. 128-bitów nie wydaje się dużym narzutem pamięci, należy jednak pamiętać, że mówimy tutaj o nagłówku, który dokładany jest do każdego jednego obiektu. W wielu zastosowaniach np. gdy tworzone jest wiele malutkich obiektów (twórcy powołują się np. na machinę learning), ten narzut staje się bardzo istotny, stąd prace nad Liliputem.
Przyglądnijmy się zatem, co przynosi JEP 450. Ogólnie rzecz biorąc, zmniejszenie rozmiaru nagłówka zostało osiągnięte dzięki starannemu przeprojektowaniu struktury nagłówka obiektu i niezbędnym ulepszeniom w podstawowych funkcjach JVM w celu obsługi kompaktowego formatu nagłówka. W obecnym modelu nagłówek obiektu składa się z dwóch części: słowa znacznika (mark word) i słowa klasy. Słowo znacznika zawiera informacje takie jak informacje o przejściu Garbage Collectora czy hashcode. Słowo klasy następuje po słowie znacznika i zawiera informacje o wskaźniku klasy. Nowy kompaktowy format nagłówka łączy słowa znacznika i klasy poprzez zmniejszenie rozmiaru hashcode i przeniesienie wskaźnika klasy do słowa znacznika, zasadniczo zmniejszając narzut nagłówka.
Jednak to, co chyba najciekawsze, to bardzo pokaźna sekcja ryzyk, szeroka jak nigdy. Nie ma się jednak co dziwić – grzebiemy tutaj w „bebechach” samego JVM, niżej zejść już trudno. Na wspomnianej liście znajdziemy choćby
- ograniczenie przestrzeni dla dalszego rozwoju języka
- potencjalne błędami w funkcji i starszym kodzie
- możliwe wprowadzenie problemów z wydajnością z powodu wymaganych refaktoryzacji
- brakiem wsparcia i ograniczeniami kodowania dla skompresowanych wskaźników klas
a jest tego sporo więcej.
Jednocześnie twórcy się nie poddają, bo potencjalna nagroda jest pokaźna – według pierwszych testów, mówimy tu nawet o 20% procent redukcji zajęcia pamięci, a to już gra warta świeczki.
Jeśli powyższe zmiany Was zaciekawiły, jak zwykle po więcej szczegółów odsyłam do oryginalnego JEP-a, ale również filmiku Java Newscast, który prezentuje w detalach poszczególne zmiany:
Źródła
- JEP 450: Compact Object Headers (Experimental)
- Save 10-20% Memory With Compact Headers – Inside Java Newscast #48
3. Release Radar
Dawno nie było release radaru i nazbierało się nam nowinek. I bardzo dobrze – każda z prezentowanych dzisiaj nowości jest bowiem w najgorszym przypadku interesującą ciekawostką, a potencjalnie może być bardzo użyteczna.
Azul Zulu JDK 17 ze wsparciem CRaC
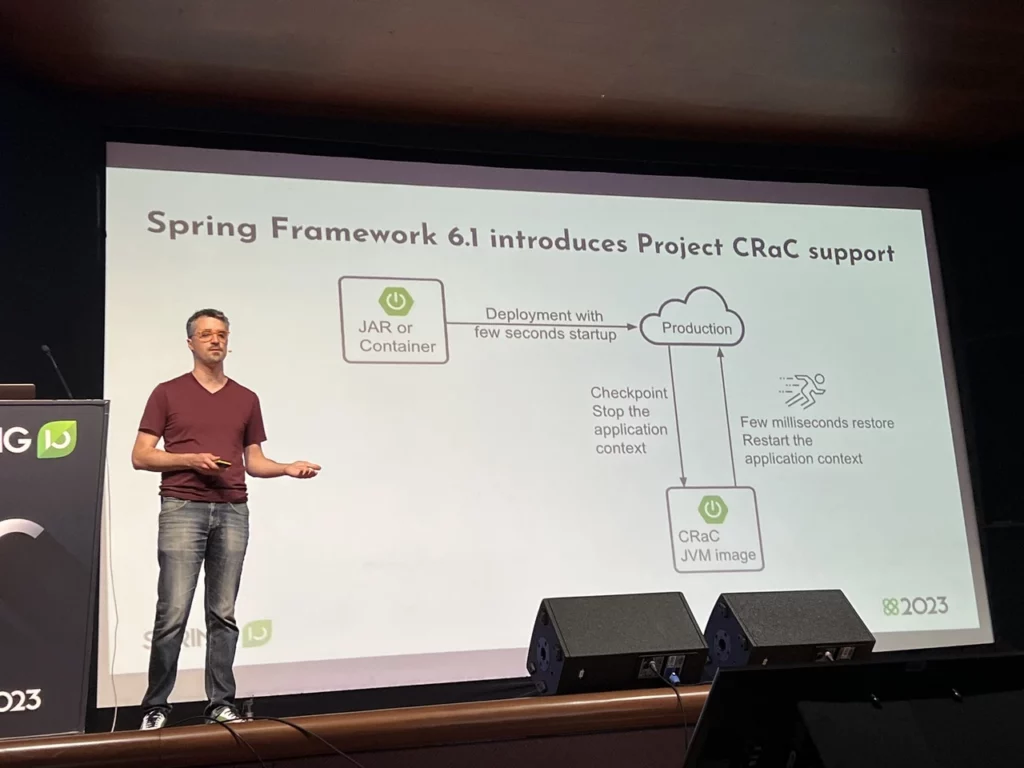
Pierwszy release pozostawi nas w świecie JDK. Azul ogłosił bowiem wydanie swojej OpenJDK 17 – Zulu – zawierającą wbudowaną obsługę CRaC API.
Dobra, dużo ale czym ten CRaC jest? CRaC API pomaga koordynować JDK i zasoby aplikacji z mechanizmum checkpoint/restore Checkpoint/Restore in Userspace (CRIU). Pozwala on na utworzenie „checkpointu” – czyli wspomnianego zrzutu pamięci – w dowolnym momencie pracy aplikacji zdefiniowanym przez twórcę oprogramowania. Dzięki niemu aplikacje Javowe mogą uniknąć długiego uruchamiania i procesu “rozgrzewania”, zapisując pełny stan środowiska uruchomieniowego.
Mam wśród czytelników jakichś retro-graczy? Jeśli tak, to całość działa w podobny sposób jak funkcjonalność Save State w emulatorach. Klasyczne zapisywanie (jak w nowoczesnych grach) wygląda tak: wybieramy te fragmenty, które pozwolą nam później odtworzyć stan aplikacji, i tylko je zapisujemy. Save State nie bawi się w takie finezje – jako, że komputery poszły do przodu i mamy więcej przestrzeni dyskowej, to po prostu zrzucamy cały stan pamięci na dysk i potem sobie odtwarzamy 1:1 gdy jest to potrzebne.

Oczywiście CRaC posiada pewnie ograniczenia (w końcu samo środowisko uruchomieniowe może się zmienić, dodatkowo utrudniona jest randomizacja). Całość już dzisiaj napędza jednak choćby Amazon Lambda SnapStart, a poszczególne frameworki chwalą się swoimi eksperymentami z narzędziem, którego użycie daje ponoć naprawdę dobre wyniki:
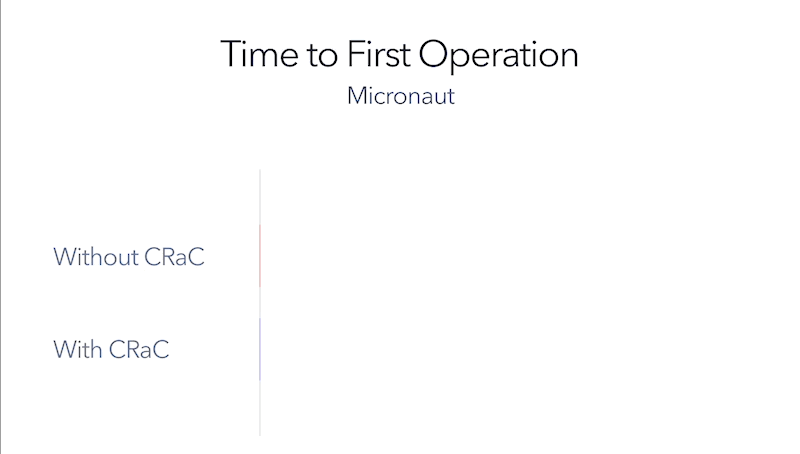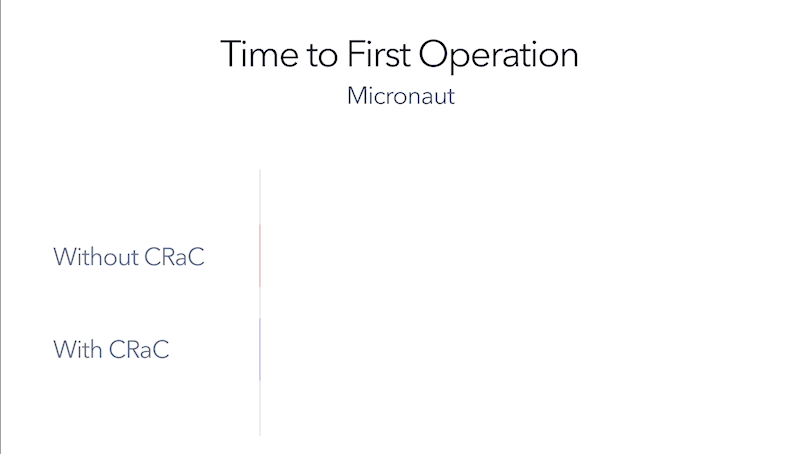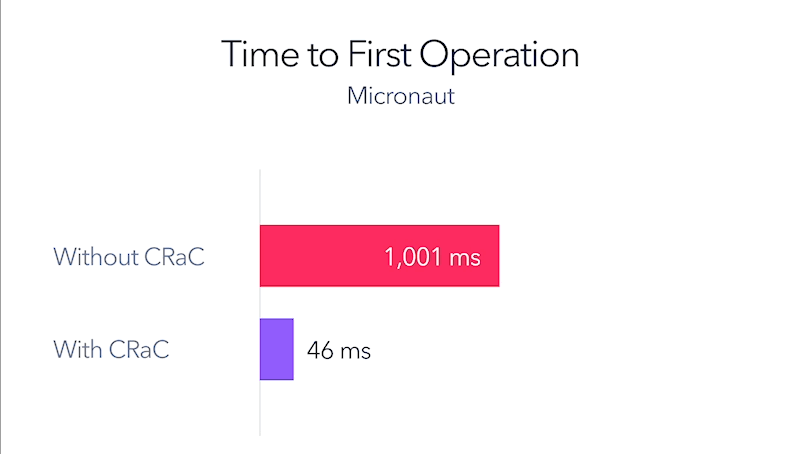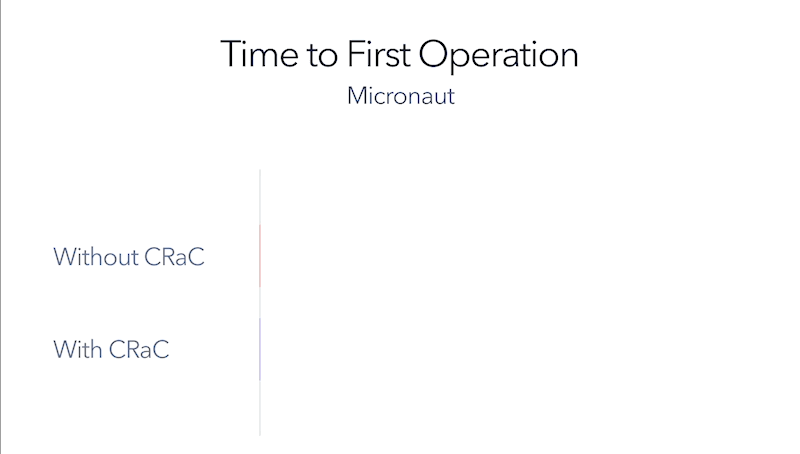
Od samego początku za projektem stał Anton Kozlov z Azul, także pojawienie się wydania nie powinno nikogo zaskakiwać. Na mój stan wiedzy Azul jest jednak pierwszym dostawcom, który zapewnia komercyjne wsparcie dla tej technologii.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
MicroStream 8.0
MicroStream to system in-memory persystencji dla grafów obiektów, pozwalający na ich wydajne przechowywanie, ładowanie, querowanie. Został zaprojektowany tak, aby zminimalizować potrzebę mapowania obiektowo-relacyjnego (ORM), co daje twórcom spore zalety jeśli chodzi o wydajność rozwiązania, a także upraszcza model danych. Dodatkowo, całość dostarczana jest w formie biblioteki, więc łatwo można dołożyć ją do istniejącego projektu.
MicroStream v8.0 wprowadza wsparcie dla Lazy Collections, takie jak LazyArrayList, LazyHashSet i LazyHashMap, mogą ładować dane do pamięci w momencie gdy te są potrzebne, przy tylko nieznacznym zwiększeniu czasu dostępu. Dodatkowo, dane mogą być łatwo czyszczone Garbage Collector, gdy zużycie pamięci jest wysokie, co sprawia że są bardzo dobrą opcją do implementacji cache aplikacji. Całość przechowywana jest w segmentach, a użytkownik może kontrolować liczbę elementów w każdym z nich, choć twórcy zachęcają raczej do używania ich domyślnych rozwiązań.
JavaMelody 2.0
JavaMelody to narzędzie do monitorowania i profilowania wydajności, przeznaczone głównie dla aplikacji Java i Java EE. Jest to raczej mało znany projekt, ale łączą mnie z nim szczególne więzi. Pamiętam, że w mojej pierwszej pracy z Java EE pierwszym zadaniem które miałem była właśnie jej integracja z projektem za pomocą mechanizmu Rozszerzeń.
Przyznam, że od tamtej pory nie słyszałem o niej za wiele, dlatego też sporym zaskoczeniem był dla mnie fakt ogłoszenia wydania 2.0. Jak łatwo się domyśleć, podbicie numeracji związane jest z przejściem na Jakarte EE 10 i nowy pakiet jakarta.* (myślę, że już dobrze kojarzycie ten wzorzec, wielokrotnie już to przerabialiśmy). Z tego też zresztą względu JavaMelody 2.0 wspiera jedynie Spring Boot 3+ – jeżeli ktoś chce pozostać na wcześniejszej wersji Springa, musi pozostać na JavaMelody z gałęzi 1.9.x.

kotlinx.coroutines 1.7.0
Na sam koniec zostawiłem sobie Kotlina. W ostatnim czasie pojawiła się bowiem nowa wersja Korutyn. Nie wszyscy mogą sobie bowiem zdawać sprawę, że choć kortyny są częścią Kotlina, to ich cykl wydań pozostaje niezależny w stosunku do samego języka. Mimo, że od dawna cieszymy się Kotlinem w wersji 1.8, to niedawno dostaliśmy w swoje ręce kotlinx.coroutines 1.7.0. Co przynosi?
Najciekawszą zmianą jest nowa implementacja Channel API (kanałów). Nowa struktura danych ma na celu naprawienie problemów z poprzednią implementacją. Poprzednia implementacja miała problemy z poprawnością, łatwością utrzymania i wydajnością. Nowa implementacja wykorzystuje struktury danych oparte na tablicach oraz wydajniejszych algorytmy pobierania i dodawania elementów. Nowe kanały są wynikowo znacznie szybsze zarówno w użyciu sekwencyjnym, jak i w przypadkach zrównoleglonych. Zmiana ma charakter techniczny i nie wpływa na użytkowników. Całość algorytmu jest na tyle nowatorska doczekała się publikacji akademickiej: Fast and Scalable Channels in Kotlin Coroutines.

Z innych ciekawy dodatków, doczekaliśmy się także usprawnienia mechanizmu Mutexów, poprawek w kotlinx-coroutines-test (zwłaszcza w kontekście lepszego wsparcia Timeoutów), a Kotlin/Native doczekał się wsparcia dla Dispatchers.IO.
PS: Takie maile to ja lubię dostawać ❤️. Jest nas wielu!
Dziękuję Wam za zaufanie.
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


