What would a week be without a new project in Java? That’s why today we’ll discuss Project Babylon, among other topics.

1. Chance for LINQ (and not only) on JVM – Project Babylon
I’ve already had occasion to mention how much I appreciate creativity in java project naming? Well, I have to do it again. Last week, Paul Sandoz, Java architect at Oracle, suggested starting a new Java project called Babylon. Why do I like this name so much? You’ll find out at the end of the paragraph. But in the meantime…
Remember how we discussed the ongoing efforts to enhance Java’s GPU capabilities in the previous edition? You might recall that TornadoVM was working in the background, transforming Java code into a format that specific hardware architectures could understand. But imagine if there was a system that could not only adapt to the instructions of various chips (like GPUs or FPGAs), but also dynamically generate native code for other runtime environments, or even SQL queries, similar to the functionality of LINQ in C#?
For individuals who haven’t interacted with C# before, here’s a demonstration of how to utilize LINQ:
DataContext dataContext = new DataContext();
// LINQ Query
var query = from student in dataContext.GetTable<Student>()
where student.FirstName == "Artur"
select student;
// Execute the query and print the results
foreach (var student in query)
{
Console.WriteLine("ID: {student.Id}, First Name: {student.FirstName}, Last Name: {student.LastName}");
} In the provided code, the LINQ query is looking for all students with the name „Artur” in the Students table. The query is run when it’s iterated over using a foreach loop. At this point, the LINQ to SQL process converts the LINQ query into an equivalent SQL query, which is then dispatched to the database.

Babylon strives to enable of building such mechanisms, showcasing what it refers to as 'code reflection’. To understand what this means, we need to return to the fundamentals. In programming languages like Java, reflection gives programs the capacity to examine and alter their own structures. In Java, reflection is presently utilized to analyze classes, interfaces, fields, and methods during execution time without the need to know their names at compile time. It’s akin to having the capability to understand the properties of a class or object and manipulate them while the program is in operation.
However, the concept of 'code reflection’ within the scope of Project Babylon, seeks to advance beyond this basic level. Instead of merely analyzing and modifying pre-compiled code structures, code reflection strives to offer a more comprehensive and adaptable access to the actual source code. It’s almost as though the software has the ability to read, analyze, and alter its own source files.
This is a simplified explanation of how code reflection would function in Project Babylon: Initially, a program model would be created, which is a representation of the Java code in a structured format, similar to a detailed building blueprint. This blueprint, known as a 'code model’ (which I believe is akin to an Abstract Syntax Tree), displays the structure of the code and its operations. Subsequently, the existing Java reflection capabilities would be enhanced, enabling not just the examination of compiled structures, but also the access to the aforementioned code model, both at the time of compilation and during execution. Additionally, there would be APIs that would enable developers to scrutinize code models, make alterations to them, and then convert those changes back into executable code.
The idea of code reflection in the Babylon Project for Java is to offer comprehensive access to and control over source code, essentially a self-altering and introspective feature. Picture a Java coder creating code intended for a graphics card (GPU). Through code reflection, the Java software could examine its own code, comprehend it, and then modify itself to be fine-tuned for the GPU, all without requiring manual transformation by the coder. The goal is to equip Java with the capacity to adapt based on particular usage.
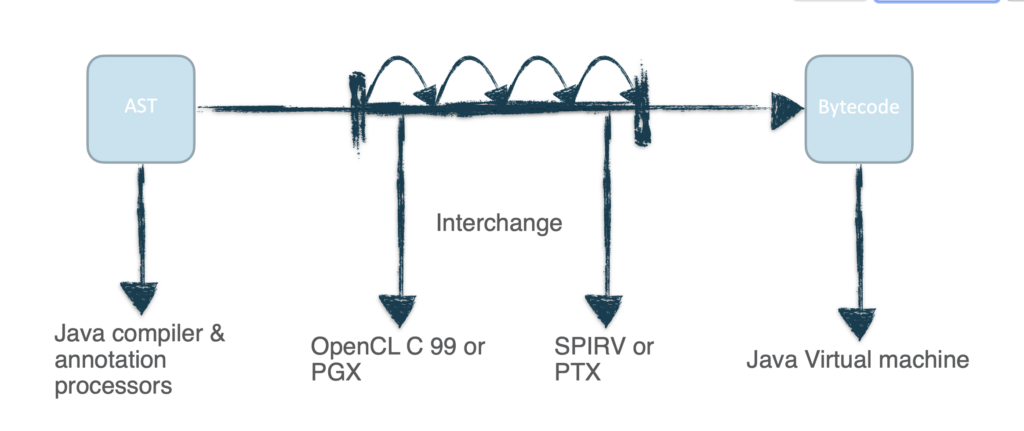
Compared to other JVM languages like Kotlin, Scala, and Clojure, which already possess features enabling meta-programming or a macro system to aid in code 'introspection’ and transformation, Babylon’s approach to code reflection strives to establish a standard mechanism. It aims to elevate Java’s reflection capabilities to the same level, or even surpass, other JVM languages. If this topic has sparked your interest, I encourage you to view a video presentation from JVMLS about Code Reflection found here:
As promised, here’s a fun fact about naming: „Babel” and „Babylon” originate from the biblical tale of the Tower of Babel in Genesis. As most people likely know, in this narrative, individuals speaking a single language attempted to construct a tower in the city of Babel to reach the heavens. Their ambition led to God confusing their language, resulting in multiple languages and the dispersion of humans across the globe. In a way, the Babylon project aims to do the reverse: it seeks to unify various programming 'languages’ or models, making them more consistent within the Java framework
However, the story doesn’t end here. The English terms 'Babel’ and 'Babylon’ originate from the Hebrew word 'Bāḇel’ (בָּבֶל), which has connections to the ancient city of Babylon. This city, located in Mesopotamia, was renowned for its cultural and historical importance. In history, Babylon served as a convergence point for various cultures, languages, and knowledge in ancient Mesopotamia. In a similar vein, the Babylon Project seeks to unify different programming models, thereby enhancing Java’s versatility and relevance to a range of paradigms.
Or am I overcomplicating things for myself 🤷.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Another method to optimize Cold Start in Java – Azul Platform Prime
I was contemplating if I should incorporate this news into the new edition, as it pertains to a solution that is highly specific to the Azul platform. However, it seamlessly integrates into the overall image of cloud Java in the widest sense. Hence, I chose to share some details about the recently announced Azul Platform Prime.

Also to the point: The JVM begins each new application run as if it were a blank slate, with no recollection of its past activities. This way of operating results in a necessary initial 'start-up’ each time to reach optimal performance. During this period, issues impact application responsiveness, like noticeable CPU load spikes during JIT optimisation, or unusual latency spikes may arise. To tackle these problems, developers frequently resort to workarounds such as manually 'warming up’ the application before it goes live. However, these solutions increase operational complexity and cost.
Azul explored the topic and integrated Azul Platform Prime with ReadyNow technology. ReadyNow gathers profiling data from the JVM session, enabling future runs to bypass the lengthy profiling phase and commence compiling immediately – somewhat similar to PGO from GraalVM or the profiling suggested by Project Loom’s developers. To me, the entire process also resembles CRaC, but it halts a step earlier – rather than 'dumping’ all the JIT-compiled code to disk, the project stores the 'input’ to the compilation process.
Well, it appears to me that this is a particularly intriguing new piece in the overall ecosystem, which is the reason I chose to dedicate this section to it. Additionally, if you believed I was overreaching with pop culture references, Azul successfully incorporated a nod to Nolan’s Memento in their announcement and I respect that, as it’s my second favorite movie from the director, following closely behind „Interstellar”.

3. Release Radar
Micronaut 4.1.0
The Micronaut Foundation has released Micronaut 4.1.0. One of the most important new features are the Bean Mappers annotated as @Introspected (the second time I’ve used that word today), which facilitate automatic mappings between different types, based on the Expression Language introduced in version 4.0 that works at compile time, without the use of reflection and ensures type safety. The framework also introduces IntrospectionBuilder for dynamically generating constructors for specific types using the @Introspected annotation.
Support for KSP (Kotlin Symbol Processing API) has been significantly enhanced, particularly for those developing Micronaut applications using this successor to the annotation processor, which is touted as superior by newer versions of Kotlin. Furthermore, modules such as Micronaut Data, Micronaut Serialisation and Micronaut Kafka have been updated with new versions, with the latter introducing significant improvements concerning Kafka offsets. Micronaut OpenAPI continues to enhance OpenAPI documentation generation at compile time, and Micronaut RabbitMQ introduces features related to the AMQP mandatory flag and RabbitMQ consumer events.
However, the list of new features does not end there. Micronaut Security now offers better debugging capabilities, especially during login failures. A noticeable change came in the integration with Neo4j, which migrated to Neo4j Testcontainers and removed dependencies on EmbeddedNeo4jServer.
Hibernate 6.3
The latest version of the Hibernate ORM 6.3.0, aligns the framework with the Jakarta Persistence 3.2 standard. This is evident in the support for numeric literals (such as 123L symbolising long) in HQL/JPQL queries. This version also introduces syntax standardisation for BigInteger and BigDecimal.
The query capabilities in Hibernate have been enhanced. A notable addition is the creation of DAO-style methods for Named Queries, facilitated by the JPA static metamodel generator, which simplifies their usage.
List<Book> books =
Book_.findByTitleAndType(entityManager, titlePattern, Type.BOOK);
Finder methods have also been introduced, where the new @Find annotation allows arbitrary methods to be processed by the generator, creating query-like methods. Support for dynamic fetching for SUBSELECT queries, meanwhile, introduces a more flexible fetching style, allowing developers to define profiles that control which links are loaded at execution time.
@FetchProfile(name = "EagerBook")
@FetchProfile(name = "EagerBookWithSubselect")
@Entity
class Book {
@FetchProfileOverride(profile = Book_.EAGER_BOOK_WITH_SUBSELECT, mode = SUBSELECT)
Set<Author> authors;
}
Session session = ...;
session.enableFetchProfile( Book_.EAGER_BOOK_WITH_SUBSELECT);
An important feature introduced in this version is also the capability to form criteria directly from HQL, and the newly added CriteriaDefinition class makes handling these criteria more straightforward. The implementation of the StatelessSession.upsert() function, on the other hand, simplifies the execution of SQL-like operations UPSERT/MERGE using StatelessSession.
For the adoption of the new version of Hibernate, it will also be important to release of the new version two new guides: one offers an introduction to Hibernate 6 and the other delves into the syntax of the Hibernate Query Language.
Quarkus 3.3.0
Quarkus has announced its latest release, Quarkus 3.3.0. It introduces a number of enhancements, including OpenTelemetry version 1.28, the Pulsar extension in Reactive Messaging, various security-related improvements, especially in OIDC, and a switch from the deprecated Elasticsearch high-level-rest-client extension to the newer Elasticsearch Java Client extension. Furthermore, developers using REST Client Reactive can now customise ObjectMapper when using REST Client Reactive Jackson. The latest iteration of Micrometer allows customisation of MeterRegistry and introduces metrics for Netty.
A significant shift has taken place in how GraalVM is defined. Quarkus has altered its dependencies, transitioning from an unofficial svm artifact to an official GraalVM SDK named org.graalvm.sdk:graal-sdk. The dependencies of this artifact in Quarkus are labeled as provided, indicating that they are not automatically incorporated into the project. Luckily, org.graalvm.sdk:graal-sdk is included in the Quarkus BOM, so there’s no need to specify its version when adding it to your project. However, if you need to use GraalVM substitutions in your applications, you’ll have to manually add the relevant dependency.
For those who are ambitious: What exactly are substitutions in GraalVM?
Substitution is a process that enables developers to alter or override classes, methods, or fields during the native image generation process. This mechanism provides a solution to issues or allows for code optimization when transforming Java applications into native executables using the Native Image tool in GraalVM. Through substitution, developers can designate that a specific class, method, or field should be substituted with an alternative implementation suited for the native environment during the native image building process, without the need to modify the original source code or wait for updates from library developers.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
Bonus: What is the future of Java in today’s enterprise?
Alright, and ultimately, a small announcement.

Recently, I’ve had the chance to become the Head of Java/Kotlin Development at VirtusLab, the company responsible for, among other things, the Scala compiler. This gives me a unique chance to promote the latest developments in the Java world – all those features I regularly write about – among businesses and see how they are actually being used in production. That’s why last week, I published an article titled What is the future of Java in today’s enterprise?. In this article, I tried to explain to the broader business audience how the recent updates to the language, JVM, and ecosystem translate into real-world applications. The initial feedback was positive, so I decided to give it a little #selfplug.
So, if you’re looking for a way to share some of the knowledge from this newsletter with decision-makers, I recommend checking out this publication 😃
PS: A prize for those who have made it through – the phrase from the Gru meme translates to „The workers are speaking new languages” in ancient Greek 😃 PS2: No need for gratitude 😃
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


