Na starcie chciałem Was przeprosić za ostatni brak regularności, który jest spowodowany zbiegnięciem się mojego urlopu i dnia wolnego w Polsce. Postaram się jednak od przyszłego tygodnia już wrócić do regularnego, wtorkowego trybu wydawniczego.

1. Wydano JDK 21 Release Candidate
Tutaj będzie dość krótko, ale jest to informacja, której nie chciałem sobie odpuścić – pojawił się bowiem pierwszy Release Candidate JDK 21, wersji, na którą masa osób sobie ostrzy zęby. Zdecydowanie nie będę próbował teraz rozbijać jesiennej Javy na poszczególne przychodzące z nią funkcje (to zrobiłem już przy okazji fazy Rampdown, a przyjdzie na to pewnie czas i przy wydaniu wersji Stabilnej). O ile publikacje Thomasa Schatzla na temat Garbage Collectorów pozostawię sobie już na wspomniany finalny release, to podzielę się kilkoma dość obiecującymi liczbami.
Dla ludzi lubujących się w benchmarkach mam bowiem dobre informacje na temat projektu Panama. Jeszcze w 2019 (te obecne projekty Javowe są już z nami trochę czasu, co nie?) Alexander Zakusylo porównał wydajność kilku dostępnych w ekosystemie rozwiązań do robienia natywnych zapytań. Pod jego lupą znalazło się siedem różnych podejść min. JNI, BridJ czy właśnie Panama – dokłada opis poszczególnych znajdziecie w oryginalnym tekście. Jeszcze cztery lata temu, Panama pozostawała wielokrotnie wolniejsza od liderów stawki. Żyjemy jednak w 2023 i widać, że kolejne wersje preview nie poszły w las – Alexander zdecydował się jeszcze raz przeprowadzić testy, tym razem z najnowszą iteracją pochodzącą z JDK 21… i Panama wskoczyła na szczyt rankingu. JDK Foreign Function/Memory API Preview (JEP-424) działają około dwa razy szybciej niż JNI.
Oczywiście, jest to pojedynczy benchmark (a pewnie już niedługo należy spodziewać się wysypu następnych), ale dobrze obrazuje przeskok wydajnościowy w projekcie.

Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Pi4J Operating System for Java development on Raspberry Pi
Przez chwilę wydawało się, że czasy, gdy Raspberry Pi było przystępnym, tanim komputerem już chyba minęły, aczkolwiek ostatnimi czasy wygląda na to, że powoli ceny zaczynają spadać, przynajmniej w Polsce. Mimo, że od 2019 nie było kolejnej iteracji, w dalszym ciągu to jednak zaskakująco potężna maszyna, która u mnie służy jako sterownik do infrastruktury sieciowej, VPN, serwer Plexa oraz Home Assistanta… równocześnie.
Nie powinno zaskakiwać, że doskonale sprawdza się jako komputer do nauki programowania.
System Raspberry Pi (OS) został zaprojektowany specjalnie dla programistów JVM za sprawą inicjatywy Pi4J. Projekt Pi4J ma swoje korzenie u Pascala Mathisa, studenta z Uniwersytetu FHNW w Szwajcarii, który zainicjował go, aby móc kontrolować elementy I/O Raspberry Pi (takie jak GPIO, SPI, I2C, SERIAL) przy użyciu Javy. Dieter Holz, wykładowca na FHNW, rozbudował tę inicjatywę, opracowując różnorodne edycje systemu operacyjnego, aby dostarczyć swoim studentom najlepsze środowisko pracy. Chodziło o to, by studenci mogli skupić się na programowaniu, nie martwiąc się o konfiguracje Linuxa i powiązane z nim narzędzia.
Zamiast stanowić zupełnie nowy system operacyjny, Pi4J OS jest odgałęzieniem oficjalnego systemu operacyjnego Raspberry Pi z zintegrowanym projektem Pi4J. Oznacza to, że jest on wyposażony w dodatkowe narzędzia i ustawienia dostosowane dla developerów Java i JavaFX. Już od momentu instalacji zawiera wszystkie elementy potrzebne początkującemu programiście. Co więcej, Pi4J ułatwia obsługę komponentów Raspberry Pi, co czyni go idealnym dla tych, którzy chcą rozpocząć swoją przygodę z tym ekosystemem.
Frank Delaport z Azula jest aktywnie zaangażowany w ten projekt i prezentuje w serii artykułów na foojay.io, jak korzystać z różnych narzędzi ekosystemu JDK (takich jak SDKMan czy Kotlin) na Raspberry Pi. Jego prezentacja „Update on #JavaOnRaspberryPi and Pi4J” stanowi doskonałe wprowadzenie dla tych, którzy mają nieużywany mikrokomputer leżący w szufladzie i chcą go ożywić.
3. Release Radar
Liberica JDK Performance Edition
Zacznijmy od dość nietypowego projektu. BellSoft, o której to firmie nie raz zdarzyło mi się już pisać, wydał Liberica JDK Performance Edition. Pod tą nazwą kryje się JDK 11 zmodyfikowana poprzez integrację z poprawkami wydajnościowymi maszyny wirtualnej pochodzącymi z JDK 17. Ten oryginalny koncept pozwala użytkownikom cieszyć się wzrostem wydajności do 10-15%, bez konieczności dokonywania jakichkolwiek znaczących zmian w kodzie. Jak łatwo się domyśleć, rozwiązanie jest skierowane szczególnie do firm korzystających z JDK 11, które mogą być niechętne lub niezdolne do przejścia na nowsze wersje. Do zbackportowanych ulepszeń należą m.in. poprawki do Garbage Collectorów czy lepsze wsparcie dla NUMA (Non-Uniform Memory Access).
Dostępna od 1 sierpnia dla obecnych subskrybentów Liberica JDK, ta edycja jest oferowana bez dodatkowych opłat, w zestawie z innymi narzędziami od BellSoft. Zastanawiam się, czy w przyszłości będziemy świadkami pojawienia się więcej takich propozycji? Kluczową kwestią wydaje się być odpowiedź na pytanie, które teraz mnie najbardziej intryguje – jakie projekty wybierają JDK z backportowanymi funkcjami VM zamiast prostego przejścia na JDK 17? Jeżeli macie doświadczenie w tej kwestii, chętnie usłyszę Wasze historie.
Fury
Teraz wchodzimy w rejony, których zawsze się nieco obawiam – serializację. Raz już przejechałem się na nowej bibliotece w tym temacie, więc każdemu rozwiązaniu przyglądam się bardzo, bardzo uważnie. Bo powiedzcie mi, jak nie być sceptycznym, gdy widzi się to:
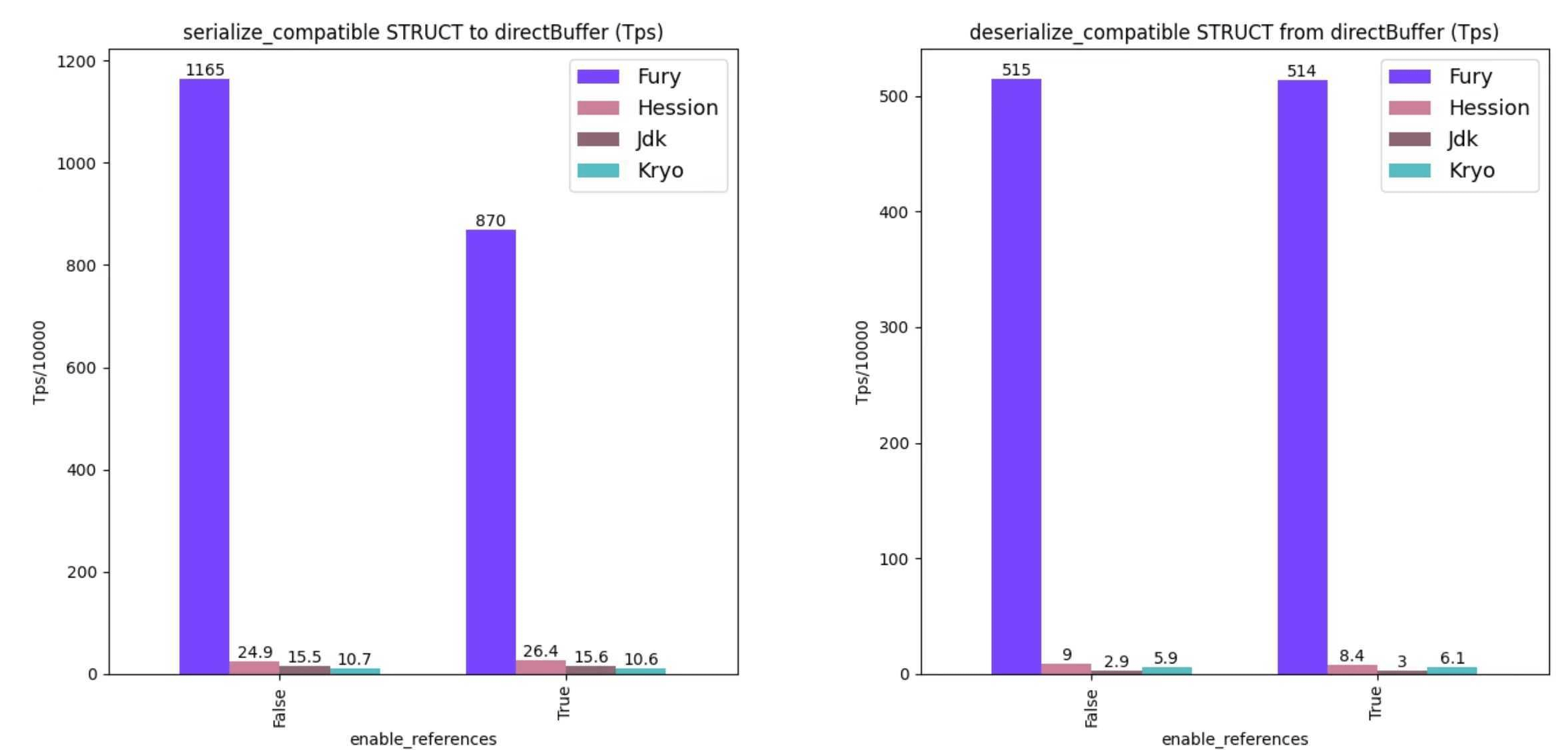
Wygląda jednak na to, że stworzony przez Ant Group Fury jest rozwiązaniem bardzo legitym. Twórcy zresztą pokusili się na dokładne wytłumaczenie, skąd biorą się takie a nie inne benchmarki w świetnym blog poście: Fury – A blazing fast multi-language serialization framework powered by jit and zero-copy. A ja teraz spróbuje wyjaśnić to Wam, co wymagało ode mnie pewnego doktoryzowania 😄

Dwie podstawowe metody serializacji to metody statyczna i dynamiczna. Frameworki opierające się na serializacji statycznej, jak na przykład protobuf, bazują na ustalonym z góry schemacie. Serializacja odbywa się zgodnie z tym schematem, co wymaga od nadawcy i odbiorcy jego wcześniejszej znajomości. Takie podejście gwarantuje szybkość oraz efektywność. Niemniej jednak ma swoje ograniczenia, głównie ze względu na brak elastyczności – komunikacja między różnymi językami programowania opierająca się na statycznej strukturze danych może być problematyczna, zwłaszcza gdy niezbędna jest ewolucja schematu. Z kolei dynamiczne frameworki serializacji, takie jak Serializable w JDK, Kryo czy Hessian, nie są uzależnione od stałego schematu. W trakcie działania określają one strukturę danych, co sprawia, że są bardziej adaptacyjne. Daje to większy komfort użytkowania i możliwość wykorzystania polimorfizmu. Niestety, taka elastyczność często idzie w parze z niższą wydajnością, co może stanowić wyzwanie w sytuacjach, gdy potrzebna jest duża przepustowość, np. przy masowej transmisji danych.
Fury szuka kompromisu między tymi dwoma światami, starając się połączyć zalety obu: elastyczność dynamicznej serializacji i wydajność serializacji statycznej. Framework jest zaprojektowany tak, aby oferować pełną kompatybilność z rozwiązaniami istniejącymi już w Javie, a dodatkowo posiadając też warianty dla innych środowisk. Fury wykorzystuje szereg zaawansowanych technik serializacji, a także wsparcie dla operacji SIMD. Rozwiązanie wykorzystuje też Zero-Copy (technikę przesyłania danych komputerowych, w której dane nie są fizycznie kopiowane między buforami pamięci lub innymi warstwami w systemie operacyjnym), minimalizuje opóźnienia podczas transferów danych, eliminując zbędne kopie pamięci. Dodatkowo, Fury używa kompilatora JIT, który wykorzystuje dane o typie obiektu w czasie rzeczywistym, generując zoptymalizowany kod serializacji. Framework kładzie również nacisk na efektywne wykorzystanie pamięci podręcznej, maksymalizując trafienia w pamięć podręczną danych i instrukcji CPU, oraz obsługuje wiele protokołów serializacji, dostosowując się do różnorodnych wymagań aplikacji.

Jeśli komuś nie wystarcza skompilowane przeze mnie wytłumaczenie, zapraszam oczywiście do oryginalnej publikacji. No i najważniejsze pytanie – to co, kto testuje na produkcji?
Eclipse JNoSQL 1.0.0
To teraz przechodzimy w rejony Jakarta EE. Przegapiłem bowiem wydanie JNoSQL 1.0.0, ale wykorzystam wydanie wersji 1.0.1 (oraz publikacje artykułu na DZone) na przedstawienie Wam tego projektu.
Eclipse JNoSQL to framework Java, będący zgodną implementacją specyfikacji Jakarta NoSQL i Jakarta Data. Jest zaprojektowany w celu ułatwienia integracji aplikacji Java z bazami danych NoSQL. Framework ma oferować takich funkcji jak integracja z Contextami i CDI, oraz możliwość tworzenia Java-based Query czy wzorce znane w świecie enterprise Javy jak Repozytoria i Template. Ponadto wprowadza on anotacje będące odpowiednikami tych z JPA, jak @Column czy @Entity. Te adnotacje upraszczają mapowanie obiektów Java do ponad dwudziestu baz danych NoSQL – listę znajdziecie tutaj.
Eclipse JNoSQL, 1.0.0, wprowadziło szereg usprawnień mających na celu poprawę możliwości frameworku oraz procesu integracji między Java a bazami danych NoSQL. Nowa wersja oferuje prostszą konfigurację bazy danych, zmniejszając nakład pracy związany z początkową konfiguracją. Wprowadzono też wsparcie dla Java Records, i ich bezproblemowe mapowanie na struktury danych NoSQL.
I muszę przyznać, że o ile zdarza mi się używać np. Spring Data, o tyle zawsze, kiedy biorę jakiś generyczny framework NoSQL… czuje się dość dziwnie. Mam wtedy wrażenie, że równie dobrze mógłbym używać pod spodem zwykłego PostgreSQL 🤷♂️.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
Jlama & llama2.java
W konkluzji, mamy dwa projekty o podobnej naturze, lecz w tym zawirowaniu tkwi pewna logika.
2023 rok wydaje się nadal dominować tematem Dużych Modeli Językowych, a informacje o nowych inicjatywach w tej dziedzinie pojawiają się niemal nieustannie. Jednym z najbardziej wyróżniających się jest LLaMA stworzona przez firmę Meta, stanowiąca konkurencję dla GPT od OpenAI. Niedawno Meta przedstawiła LLaMA 2, ulepszoną wersję swojego modelu. Kluczową informacją dla tego artykułu jest fakt, że ten model jest dostępny w otwartym źródle i jest licencjonowany do zastosowań komercyjnych, w odróżnieniu od jego poprzednika skierowanego wyłącznie do badań naukowych. W krótkim czasie zdobyła ona uwagę wielu podmiotów na rynku, w tym niespodziewanie Microsoftu, który współpracuje z OpenAI. Rozpoczęła się więc rywalizacja w branży, która przeniosła się również do świata Java. W tej konkurencji wyraźnie wyróżniają się dwa projekty: Jlama oraz llama2.java.
Jlama to silnik przetwarzania oparty na Javie dla LLM, kompatybilny z modelami takimi jak Llama, Llama2 czy GPT-2 (który także został udostępniony), a także z formatem modelu Huggingface SafeTensors. Aby działać, wymaga on Javy 20 oraz korzysta z często omawianego tutaj Vector API, które umożliwia szybkie obliczenia wektorowe niezbędne podczas wnioskowania z modeli. Na ten moment to główne informacje na jego temat, choć warto zwrócić uwagę, że jest on udostępniony na licencji Apache.
Z kolei llama2.java to bardziej zaawansowany projekt. Ten wspiera tylko Llama 2 – jest to bowiem bezpośredni port llama2.scala, który z kolei bazuje na llama2.c stworzonym przez Andreja Karpathy’ego. Co ciekawe, projekt ma na celu służyć jako pole do testowania nowych funkcji językowych, ale także porównywać wydajność GraalVM w stosunku do wersji w C. W repozytorium znajdują się odpowiednie testy wydajnościowe. Aby skorzystać z tej biblioteki, potrzebujesz Javy w wersji 20+, wraz ze wsparciem dla MemorySegment i Vector API.
Co edycję pojawiają się nam nowości dotyczące Javowych rozwiązań w dziedzinie sztucznej inteligencji, co napawa mnie entuzjazmem. Te projekty bowiem potwierdzają moje przekonanie: najnowsze funkcje języka otwierają drzwi przed kolejnymi zastosowaniami, a ich wpływ sięga znacznie dalej niż zwykłe słodziki składniowe. Dzięki dynamicznemu rozwojowi w ostatnich latach oraz tego rodzaju projektom, Java demonstruje, że znajduje się w czołówce narzędzi stosowanych w nowoczesnych rozwiązaniach, co skutecznie ucisza jej sceptyków, wieszczącym jej rychłą śmierć.

I tym optymistycznym stwierdzeniem żegnam się – widzimy się za tydzień (już myślę w regularnym, wtorkowym trybie)!
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


