Głównym daniem dzisiejszej edycji jest przyglądnięcie się, co jak wyglądają procesy tworzenia języka pod maską – na przykłądzie twórców Scali. Porozmawiamy jednak również o większym zaangażowaniu RedHata w Eclipse Temurin oraz o procesie zarządzania zależnościami.

1. Eclipse Temurin dostaje komercyjne wsparcie od RedHata
Zacznijmy od jedynej większemu newsowi z ostatniego tygodnia – czyli informacji o tym, że Eclipse Temurin, czyli build OpenJDK tworzony przez Adoptium, zostało oficjalnie adoptowane (hehe) przez kolejnego gracza – RedHat (zaangażowany w projekt od samego początku) zapowiedział bowiem oficjalne wsparcie komercyjne dla inicjatywy. Dla wielu z Was pewnie pojawiło się tutaj trochę dziwnych nazw, dlatego śpieszę z przypomnieniem i małym słowniczkiem.

Dmuchając na zimne: Obrazek powyżej stanowi własność firmy WarnerBros.
Pewnie większość kojarzy projekt AdoptOpenJDK, który powstał jako efekt wysiłków społeczności walczącej o “wolną” implementacje JDK w momencie, kiedy Oracle parę lat temu uczynił Oracle JDK płatnym dla użytku komercyjnego. AdoptOpenJDK początkowo rozwijany był przez społeczność JUGów z całego świata, by ostatecznie trafić pod skrzydła Eclipse Foundation. W efekcie AdoptOpenJDK zostało przechrzczone na na Eclipse Adoptium (JDK jest znakiem towarowym należącym do Oracle) oraz powstanie Adoptium Working Group.
W jej skład wchodzi wiele zaangażowanych w rozwój Javy firm, w tym wspomniany RedHat, a głównymi artefaktami pracy grupy są:
- Eclipse Temurin – oficjalna dystrybucja OpenJDK grupy, ale także cała infrastruktura do budowania i koordynację wydań.
- Eclipse AQAvit – duży zestaw testów jakościowych obejmujących funkcje, bezpieczeństwo, wydajność i trwałość oraz definiuje kryteria jakości, wymaganej przez „klientów korporacyjnych”.
- Eclipse Temurin-Compliance zapewnia, że binarki Eclipse Temurin są zgodne ze specyfikacją Java SE.
Wracając do RedHata, to ten przez wiele lat posiadał własne OpenJDK, teraz zaś zamierza skupić się na Temurinie. Oznacza to, że klienci firmy mogą liczyć na oficjalny support tego wydania i to właśnie ono ma być dostępne we wszystkich produktach firmy.

Oczywiście, RedHat nie jest w tej inicjatywie sam, a ostatnio masę energii w rozwój javowego ekosystemu wkłada też Microsoft. Robi to poprzez członkostwo we wspomnianych grupach roboczych (czy to Adoptium, czy też Jakarta EE), ale też jak najlepsze wsparcie Javy w chmurze Azure. Firmie chyba zależy, żeby o całej współpracy było głośno, bo w ramach kanałów komunikacyjnych Spring Framework pojawił się w tym tygodniu gościnny artykuł autorstwa Julii Liuson z Microsoft, podsumowujący cały wachlarz działań Microsoftu w tym obszarze. Jeżeli jesteście użytkownikami Azure, warto zerknąć, a dodatkowo tego typu „crossover episodes” zwracają uwagę na ciekawe, odbywające się w ekosystemie współprac.

Źródła
- Red Hat expands support for Java with Eclipse Temurin
- Microsoft is committed to the success of Java developers
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. A Wy co macie w swoich zależnościach? I jak to weryfikujecie?
No i jeśli chodzi o newsy, to powyższy Red Hat wyczerpał nam pulę. Ale nie samymi newsami człowiek żyje – czasem (a powiedziałbym, że niepokojąco często) to, co zaprząta jego uwagę to nie najnowsza wersji JDK, ale problemy kompatybilnościowe lub (gulp) bezpieczeństwa z zewnętrznymi zależnościami. Mam wrażenie, że w tej kwestii nasza branża porusza się między dwoma skrajnościami – projekty albo mają bardzo ścisłe reguły typu „starszyzna plemienna, która nie widziała kodu źródłowego od dziesięciu lat musi wyrazić zgodę na podbicie minora Springa” do „left-pad? A po co to pisać od zera, jak można użyć zewnętrzenej biblioteki od randoma z internetów mającej 10 linijek”
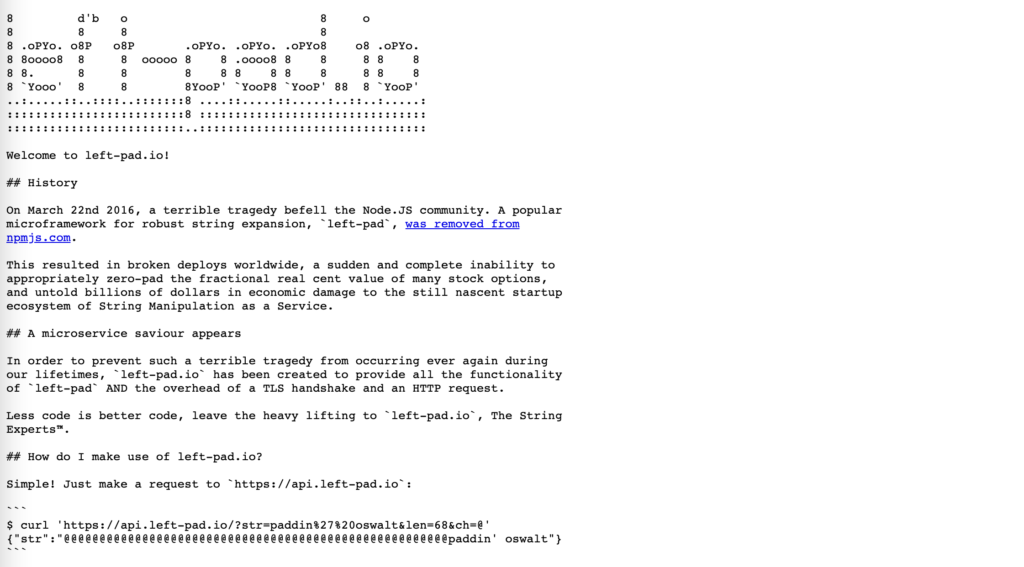
Na szczęście istnieje również trzecia droga, czyli świadome i rozsądne podejście do tematu zależności. Zdaje sobie sprawę, że każdy projekt będzie musiał sobie gdzieś stuningować, jak bardzo „na ostrzu żyletki” chce pozostawać. Jeśli jednak szukacie jakichś dobrych praktyk, które pomogą w uzyskaniu pożądanego balansu, polecam tekst Best practices for managing Java dependencies od snyk.io właśnie w tym temacie. Snyk to szeroko znana platforma zapewniająca wsparcie bezpieczeństwa w buildach programistycznych (w tym właśnie min. Skanowanie zależności). Rzeczona publikacja przedstawia zaś zespół sugestii, które warto wdrożyć w każdym projekcie.
W tekście znajdziecie sporo dobrych tipów, w jaki sposób łatwo sprawdzić poziom wsparcia używanych przez was bibliotek, to czy Wasze pakiety nie wymagają aktualizacji, oraz które pluginy do Mavena i Gradle, ułatwiające ten proces użyć. Nie zabrakło oczywiście odrobiny content marketingu, ponieważ wśród narzędzi znajdziecie również Synka, ale nawet osoby nie zamierzające dokładać nowego narzędzia do swojego toolchaina znajdą dla siebie interesujące porady.
Źródła
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
3. Jak się testuje kompilatory i projektuje cykl releasowy? Dowiedzcie się na przykładzie Scali
A na koniec będzie o Scali – w naprawdę unikalnym kontekście. Mam bowiem dla Was dwa teksty, pozwalające zajrzeć pod maskę core teamu rozwijającego sam język.

Czasem zapominamy o tym, ale kompilator to nie jest magiczna skrzynka zamieniająca kod w uruchamialną aplikację, ale również program sam w sobie. Oznacza to, że pracują nad nim zespoły programistyczne posiadające swoje własne Jiry, Sprinty i ogólnie używające normalnych metodologii wytwarzania oprogramowania. Dlatego też np. każde nowe wydanie Javy posiada swoje konkretne kamienie milowe, wymagane do stabilizacji całości wraz z odpowiednimi okresami testowania. Całość musi być też gdzieś budowana.
Zaczęliśmy dzisiejszą edycję do Eclipse Temurina, który zapewnia (poza samym wariantem OpenJDK) również infrastrukturę do budowania takowego. Dla zaciekawionych, jak tego typu proces przebiega również w innych językach, pojawia się dobra szansa aby poczytać o całym procesie od kuchni. Zespół odpowiedzialny za kompilator Scali w VirtusLab podzielił się bowiem Case Study opisującym ich podejście do testów regresyjnych kompilatora. O ile jednak Java skupia się na spełnieniu formalnej specyfikacji i tak zwanego TCK (Technology Compatibility Kit), o tyle twórcy Scali idą o krok dalej, testując swój produkt końcowy na realnych projektach open-source, dzięki czemu nabierają pewności, że wprowadzone przez ich zmiany nie popsują ekosystemu.

Jednym z moich ulubionych „praw” wytwarzania oprogramowania jest tak zwane Prawo Hyruma, określane również „Prawem Murphy’ego dla API”. Brzmi ono następująco:
Przy odpowiedniej liczbie użytkowników API, nie ma znaczenia, co obiecujesz w kontrakcie: wszystkie obserwowalne zachowania twojego systemu będą przez kogoś zależne.
Mam wrażenie, że twórcy Scali wzięli sobie je mocno do serca i działają dokładnie w tym samym duchu. Wszystkim zainteresowanym internalami narzędzi developerskich bardzo polecam lekturę samego case study, bo stanowi dość jednak unikalny wgląd w proces testowania tak krytycznego elementu ekosystemu języka, jak kompilator.
A jak już jesteśmy w temacie Scali, to ostatnio ukazały się jej długookresowe plany wsparcia. Można się z nich dowiedzieć, które wydania dostaną dłuższe wsparcie, które nie będą już rozwijane, które powinny być zaś porzucone. Twórcy Scali wprowadzają bowiem dwa typy buildów – Scala LTS (z trzyletnim wsparciem) i Scala Next, które będą od siebie dość mocno odseparowane, przy równoczesnym umożliwieniu stosunkowo prostej migracji. Nawet jeśli nie używacie Scali, to ponownie jest to kawał ciekawej lektury – tekst mocno bowiem wchodzi w niuanse tego, co siedzi w głowie twórców języka, gdy myślą oni o długoterminowym wsparciu konkretnych wersji.

Źródła
- Long-term compatibility plans for Scala 3
- Prawo Hyruma
- How to prevent Scala 3 compiler regressions with Community Build
PS: Za tydzień nie ma JVM Weekly – urlop mam 🏝
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


