W dniu dzisiejszym mamy dla Was GraalVM od Facebooka, GraphQL od Springa, a także raport podsumowujący pierwsze miesiące życia Scali 3. Zapraszamy do lektury!

1. Facebook dzieli się swoim użyciem GraalVM
W niejednej edycji naszego wtorkowego przeglądu mieliśmy już okazję pisać na temat GraalVM. Technologia ta jest jednym z najciekawszych elementów JVMowego ekosystemu ostatnich lat, a każda nowa i większa edycja wzbudza entuzjazm społeczności. I o ile ja sam miałem przyjemność wdrożenia jej na produkcję (aczkolwiek w bardzo ograniczonym zakresie – “natywny” Micronaut w Dockerze to największy możliwy graalVMowy banał), o tyle jednak na rynku ciągle brakuje jakichś ambitnych wdrożeń, które mogłyby przetrzeć szlaki kolejnym eksperymentatorom. Dlatego zawsze z zainteresowaniem przyglądam się nowym, pojawiającym się Case Study. Tym razem swoimi doświadczeniami z GraalVM postanowił podzielić się Facebook.
Facebook pewnie nie kojarzy się nikomu bardzo z JVMem. Wszystkim zdziwionym śpieszę jednak przypomnieć, że w tego typu firmach, ze względu na szerokość ich działań, znaleźć można w zasadzie każdą możliwą technologię. Cytując sam artykuł: Java jest wykorzystywana w Facebooku w kilku kluczowych obszarach: big data (Spark, Presto itp.), różnego rodzaju usługach oraz w szeroko pojętym mobile. Tego typu firmy często mają też dość unikalne wymagania jeśli chodzi o performance. Przy pewnej skali działania okazuje się, że każdy procent wydajności szybko przekłada się na wymierne oszczędności.
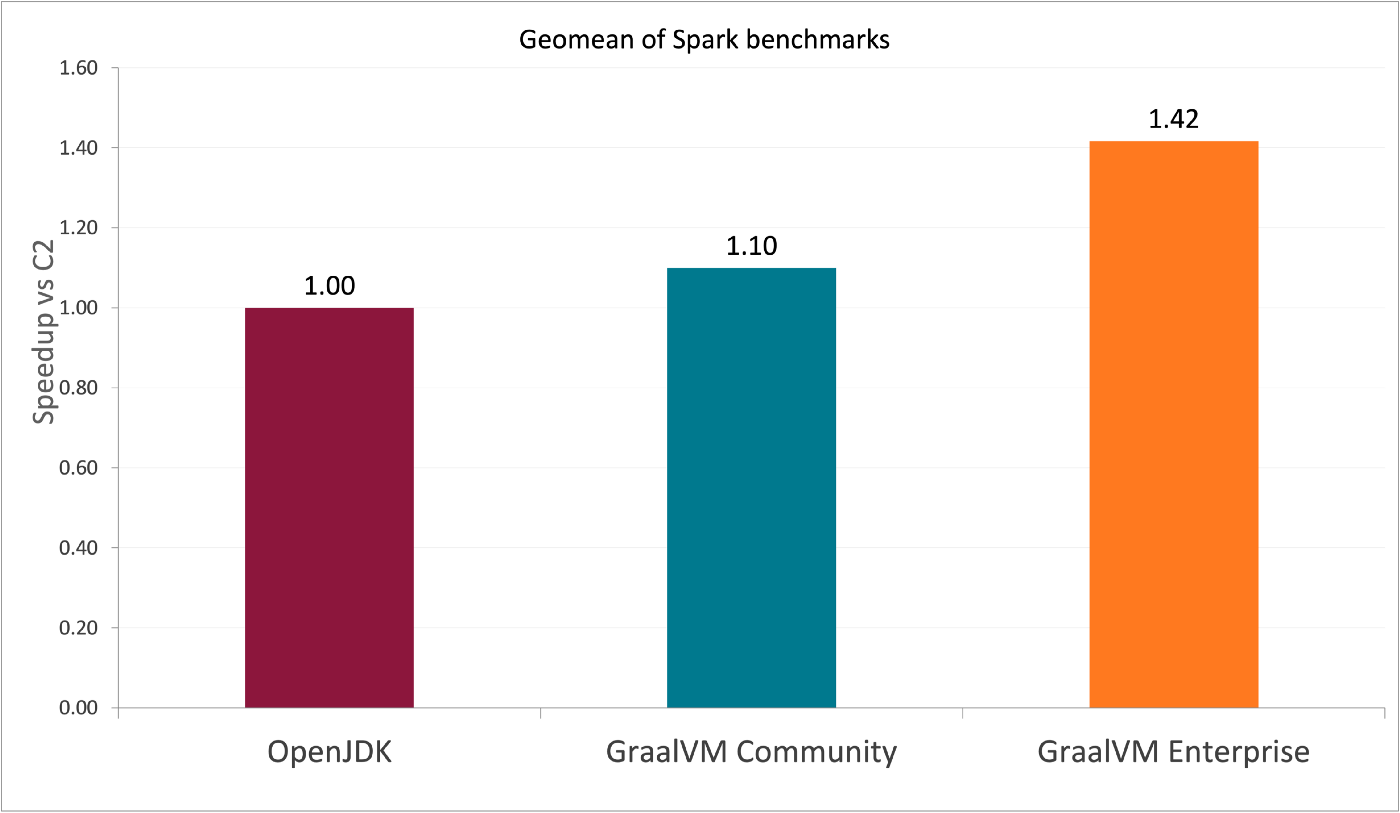
Przywołane Case Study opisuje właśnie Sparka. Artykuł nie tylko przedstawia, jakie cechy GraalVM sprawiły, że Facebook zainteresował się właśnie GraalVM, ale również pokazuje bardzo konkretne liczby. Ostatnio słuchałem odcinka podcastu Adama Biena, airhacks.fm, w którym rozmawiał on z głównym Product Managerem Graala, Shaunem Smithem. Jednym z aspektów, który przykuł moją uwagę były właśnie charakterystyki wydajnościowe – z rozmowy wynikało, że o ile już Community Edition nieco zyskuje nad OpenJDK, to dopiero płatna wersja Enterprise rozwija skrzydła. Jak udowadnia powyższy wykres, jest to zgodne z wynikami uzyskanymi przez Facebooka, co przyznam było dość miłym zaskoczeniem.

Tak jak już wspomniałem, publikacja zawiera sporo interesujących detali, dlatego polecam przeczytać pełne podsumowanie, zwłaszcza jeśli używacie Apache Sparka.
Dla chętnych – artykuł linkuje również do równie interesującego Case Study, opublikowanego już w 2017 przez inżynierów Twittera.
BTW: A jak już mowa o Sparku – w zeszłym tygodniu ukazało się stabilne wydanie kotlinowej wersji jego API. Może ktoś będzie chciał spróbować.
Źródła
- GraalVM at Facebook. Facebook is using GraalVM to accelerate…
- Kotlin API for Apache Spark 1.0 Released | The Kotlin Blog
- Podcast with Adam Bien about Java and Web
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Scala 3 Tech Report z informacjami o stanie ekosystemu ƛ
Bardzo lubimy w Vivedzie wszelkiej maści raporty. Mimo, że czasem ekstrapolują szerokie wnioski z nie zawsze wielkiej próbki (patrzę się na ciebie, Jakarta EE Survey), albo mieć tę próbkę mocno zbiasowaną w kierunku “bleeding edge” (czyli właśnie ludzi skłonnych odpowiadać na pytania w takich zdalnych raportach), ale każdorazowo potrafią przynieść nieco szerszego spojrzenia na głosy pojawiające się w społeczności. Dlatego też chętnie przytuliliśmy The Scala 3 Tech Report, wydany przez firmę SoftwareMill. Scala 3 miała bowiem niedawno premierę, więc jest to dobry moment na przyglądnięcie się jej obecnej adopcji.
Jak to zawsze w takich ankietach bywa, po części opisującej metodologie (próba raportu to 671 osób – “not great, not terrible”) dostajemy masę wykresików, ładnie wyrysowanych w oparciu o zdobyte dane liczbowe. I o ile np. użycie Scali z podziałem na konkretne branże może dla wielu osób być przydatne, to mnie zawsze najbardziej ciekawiły rzeczy nieco bliższe “maszynie” – mocno związane z ekosystemem technicznym.
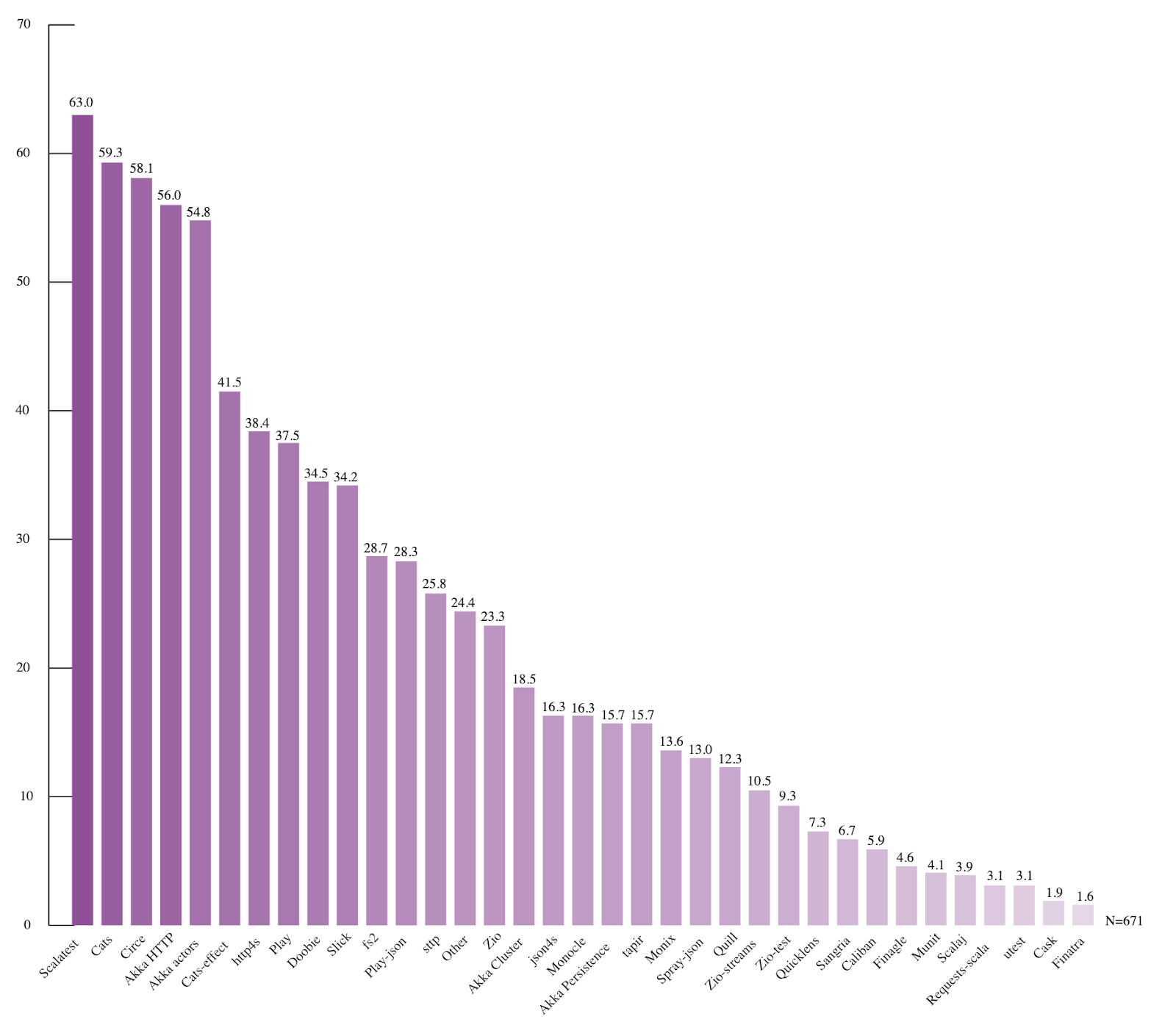
Linkowany raport zawiera parę smaczków dla takiej właśnie nerdozy jak ja. Coś, co przykuło moją uwagę, to z pewnością procentowe użycie poszczególnych bibliotek. Co prawda, na samym szczycie mamy banał, czyli Scalatest, ale z wykresów można odczytać też kilka interesujących rzeczy.
Przykładowo, w oparciu o raport rysuje się olbrzymia dominacja Cats, jeśli chodzi o rozwinięcie wsparcia Scali dla programowania funkcyjnego (Aczkolwiek trzeba też zaznaczyć, że wśród najczęściej używanych rozwiązań dalej nie brakuje tych opartych na Akkce). Zarówno Cats, jak i Cats-Effects należą do ścisłej czołówki najczęściej używanych bibliotek. Do czołówki przebiło się też Circe, współpracująca z Catsami biblioteka do parsowania JSONów. Dodatkowo to właśnie Cats i Circe są również tymi rozwiązaniami, bez wsparcia których programiści nawet nie planowali by rozważać migracji do Scali 3 – a o ile Cats w wspiera nową wersję języka, o tyle jej obsługa w Circe jest ciągle w fazie eksperymentów.
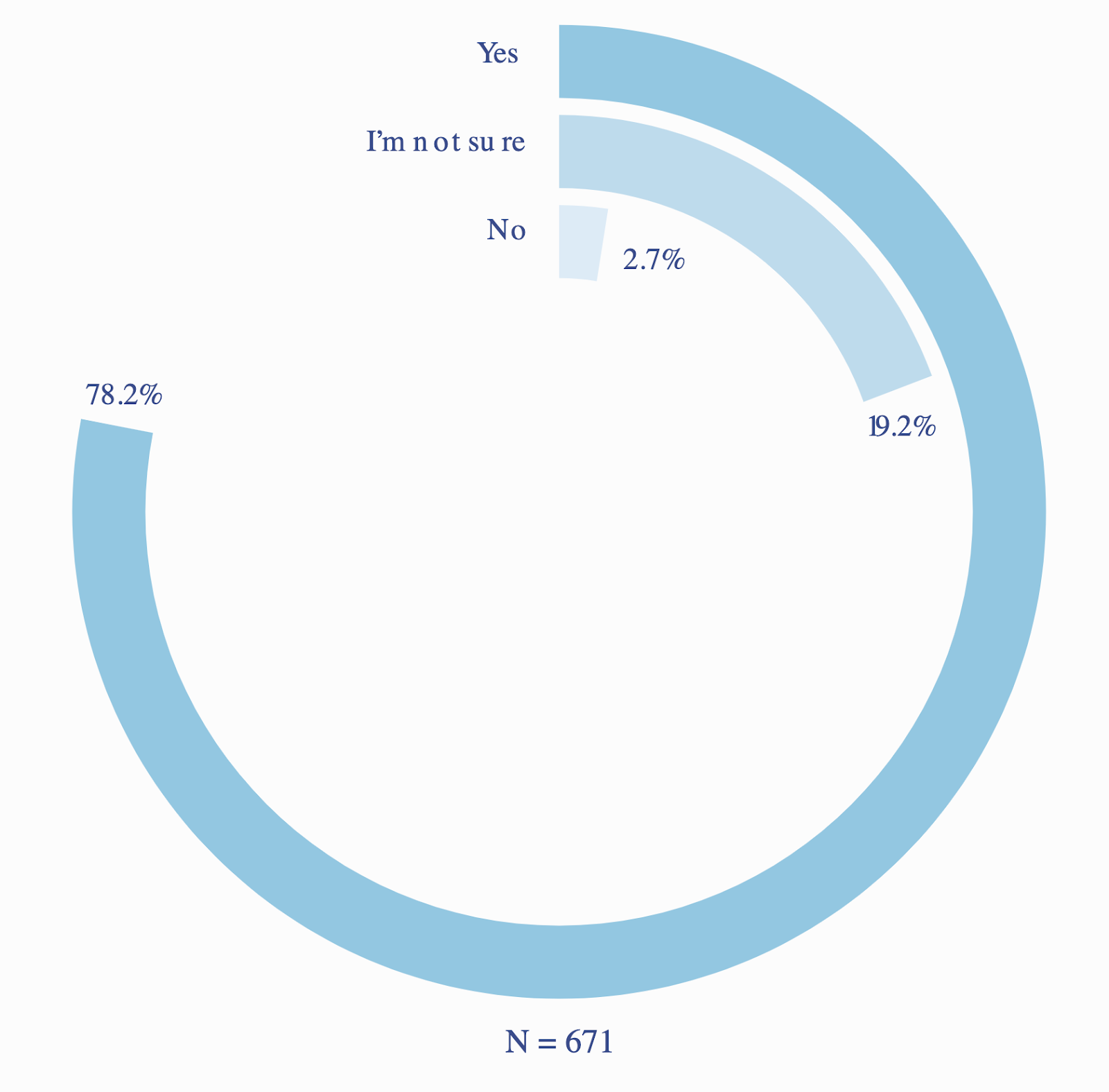
Z tego punktu płynnie możemy przejść do pytania, które najbardziej mnie zainteresowała – czy programiści zamierzają przejść na Scalę 3? Otóż okazuje się, że raczej tak – prawie 80% deklaruje taki zamiar z dużą pewnością.
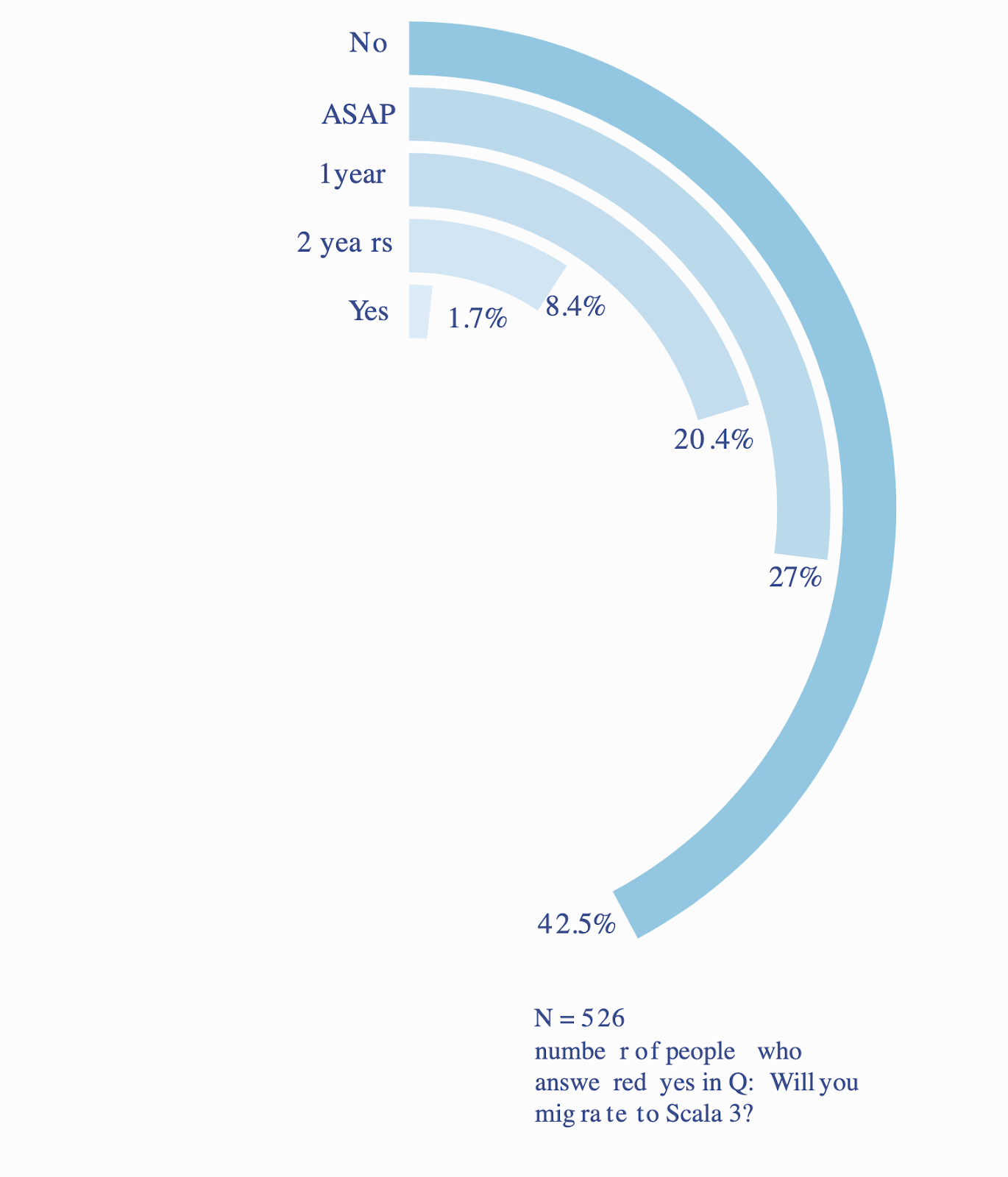
Nieco gorzej prezentują się co prawda przewidywania, kiedy może to nastąpić (prawie połowa nie ma zdefiniowanego nawet zgrubnego planu migracji), ale w dalszym ciągu wygląda to dość optymistycznie. Oczywiście, tak jak wspomniałem we wstępie, należy brać pewną poprawkę na to, że odpowiedzi prawdopodobnie dokonywała grupa najbardziej aktywnych użytkowników, więc dane mogą być delikatnie zaburzone.
Polecamy oczywiście cały raport, który jest bardzo dobrze przygotowany i nawet dla kogoś, kto nie pisze codziennie w Scali, zawiera masę interesujących informacji.
Źródła
- Scala 3 Tech Report by SoftwareMill
- https://github.com/typelevel/cats/releases/tag/v2.6.1
- https://github.com/circe/circe/releases
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
3. Natywne wsparcie dla GraphQLa w Springu
Minęło kilka lat, od kiedy pojawił się na rynku GraphQL, który zapowiadany był jako pogromca RESTa. W zasadzie od 2015 do niedawna każdy kolejny rok zapowiadany był jako ten, w którym ten nowy protokół komunikacyjny ostatecznie “zaskoczy” i zacznie szturmem zdobywać rynek. Ostatnimi czasy mam jednak wrażenie, że chęć opanowania świata, tak widoczna w początkowych latach, gdzieś wyparowała. To jednak bardzo dobrze – w jej wersji pojawiło się nieco zdrowego pragmatyzmu, który co prawda wepchnął samą technologię w pewną niszę (czy też raczej wiele różnych nisz), ale też zakończył erę promocji GraphQLa jako idealnego rozwiązania w zasadzie na wszystko. Dzięki temu na rynku pojawiło się sporo interesujących success stories, powoli onieśmielających naśladowców – przypadek nieco bliźniaczy do GraalVM z pierwszego punktu. W zeszłym tygodniu ciekawe ogłoszenie pojawiło się ze strony Spring. Zespół rozwijający framework zainicjował bowiem nowy moduł – Spring GraphQL.
Projekt ściśle integrujący GraphQL Java (najstarszą i najpopularniejszą, sześcioletnią już bibliotekę) i Springa nie powstał w próżni. Od lat powstawały różnorakie rozwiązania umożliwiające tego typu współpracę. Jednocześnie jednak żadne z istniejących rozwiązań nie zapewniało takiej wygody jak “natywnie springowe” rozwiązania. Zniechęciło to do eksperymentów i sprawiało, że próg wejścia nieraz był po prostu za wysoki. Teraz ta sytuacja ma się zmienić – aczkolwiek nie powiem, że z mojej perspektywy jakoś diametralnie.

Główna integracja używa Querydsl, który znany pewnie wszystkim korzystającym z projektu Spring Data, także jeśli chodzi o samo tworzenie zapytań nie powinno być większych problemów. Równocześnie jednak przyznam, że po przeglądnięciu się przykładom oraz dokumentacji, całość rozwiązania (oparta o Interceptory i DataFetchera) wygląda na dość skomplikowane na pierwszy rzut oka. Niestety, wysoki próg wejścia zawsze był jednym z problemów GraphQLa, ale
muszę przyznać, że rozwiązania Node.js (jak np. Apollo) wyglądają dużo bardziej przyjaźnie. Możliwe, że jednak jest to tylko pierwsze wrażenie, a po przegryzieniu się przez dość skomplikowane Hello World całość będzie przyjemna w użyciu.

Jak to w Springu bywa, rzeczona integracja to nie tylko samo wsparcie dla technologii, ale również dodatkowe elementy, niezbędne do tworzenia realnych, produkcyjnych aplikacji. Dlatego też nie brakuje wsparcia dla odpowiednich polityk bezpieczeństwa, czy zgodnych ze springowymi standardami obsługi wyjątków. Sumarycznie więc mamy do czynienia z dość ciekawą, “pełną” ofertą.
Ciekawe, czy projekt sprawi, że więcej “springowców” zdecyduje się na GraphQL w swoich projektach.
A jeśli chcecie posłuchać więcej o GraphQL to zapraszam do odcinka videocastu, w którym wraz z gościem opisujemy, czym takowy jest oraz rozmawiamy o istniejącym scalowym ekosystemie.
Źródło
Pamiętajcie, żeby spróbować Vived, jeśli chcesz otrzymywać tego typu treści spersonalizowane pod Ciebie!
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


