W dniu dzisiejszym „przekrojówka” informacji o banach, zawieszeniach i innych kontrowersyjnych działaniach. Oprócz tego tak zwany Model Spotify oraz bardzo istotne wydanie Apache Kafka.
Zapraszamy do lektury 🥳.
W dniu dzisiejszym „przekrojówka” informacji o banach, zawieszeniach i innych kontrowersyjnych działaniach. Oprócz tego tak zwany Model Spotify oraz bardzo istotne wydanie Apache Kafka.
Zapraszamy do lektury 🥳.

Zaczynamy od mojego ulubionego tricku – zebranie do kupy kilku luźno powiązanych newsów, by następnie spiąć je razem w jedną, quasi spójną narrację.
Zacznijmy więc od wydarzenia, które obiegło branżowe media chyba najszerzej.

Mówi się o tym, że jeśli projekty są otwartoźródłowe, raczej nie grożą im luki bezpieczeństwa. W końcu na takie jądro Linuxa patrzą dziesiątki programistów. Równocześnie jednak, praktyka i historia często pokazują, jak naiwne jest takie podejście. W związku z tym, uczeni z University of Minnesota postanowili sprawdzić reakcje społeczności na tak zwany „supply-chain attack” w praktyce, co doprowadziło do dość nieprzyjemnych reperkusji.
Otóż Greg Kroah-Hartman, jeden z istotniejszych commiterów linuxowego kernela zaczął zauważać, że kontrybucje ze strony rzeczonego uniwersytetu zaczęły być niskiej jakości i zawierać błędy, mogące zmniejszyć bezpieczeństwo całego jądra. Po przeglądnięciu się sprawie, on i reszta core teamu stwierdzili, że defektów jest na tyle, iż noszą one znamiona celowego działania.
Wystosowali zatem zażalenie do naukowców ze wspomnianej uczelni, którzy w odpowiedzi… zaczęli oskarżać ich o opresyjność i często zarzucaną open-source małą inkluzywność, twierdząc że kod po prostu został napisany przez uczących się studentów. W kontekście np. ostatnich problemów Richarda Stallmana tłumaczenie to było niezwykle paskudne, gdyż szybko okazało się, że zespół dopiero co opublikował na bazie swoich kontrybucji pracę „On the Feasibility of Stealthily Introducing Vulnerabilities in Open-Source Software via Hypocrite Commits„, mleczko więc szybko się rozlało.
Zespół naukowców tłumaczył się, że rzeczone działania były dokonane “w imię badań naukowych” i zatwierdzone zostały ówcześnie przez akademicką komisję etyki. Argumentacja ta nie przekonała jednak utrzymujących Linuxa i postanowili oni… dożywotnio zbanować poprawki wprowadzane do Kernela przez rzeczony uniwersytet (oraz wszystkie powiązane z nim osoby), dając w ten sposób jasny sygnał potencjalnym naśladowcom. Cała sprawa ma kilka bardzo interesujących niuansuów, polecamy jej szersze opracowanie zrealizowane przez ZDNet.

Nie był to koniec banów i kontrowersji z jakimi mieliśmy do czynienia w tym tygodniu. Otóż okazuje się, że jeden z pracowników IBM otrzymał formalny zakaz zajmowania się częścią linuxowego kernela znaną jako Virtual Network Interface Cards (VNICs) – również w czasie wolnym . Było to motywowane faktem że, cytując: “jest on pracownikiem IBM 100% czasu i nie ma prawa rozwijać kernela jako hobby”. Sprawa ma drugie dno – IBM jest mocno zaangażowany w VNIC, co może tłumaczyć takie, a nie inne działania (firma opublikowała zresztą sorry-no-sorry w najlepszym, nic nie tłumaczącym korporacyjnym stylu). Trzeba jednak przyznać, że sama narracja jest wyjątkowo paskudna dla International Business Machines.
Nienajlepszą prasę zyskał też Microsoft, wyrzucając ze swojego programu MVP (Most Valuable Professionals) Geoffreya Huntleya. Pewnie zdarza się Wam sytuacja, gdy dział marketingu Waszej firmy prosi o udostępnienie dalej materiałów w socialkach. Otóż okazało się, że Microsoft rozesłał swoim partnerom “prośbę” o opublikowanie w ichniejszych kanałach informacji o tym, że Azure jest najlepszą platformą do obsługi SQL Servera. Całość miała działać ponoć jako “atak wyprzedzający” w stosunku do zbliżających się zapowiedzi ze strony AWSa, ale Geoffreyowi bardzo się to nie spodobało, co wyraził przy pomocy swojego Twittera.
I see the microsoft #mvpaward program has completed its de-evolution into outright providing content to influencers and asking them to spread it. pic.twitter.com/SqMBSDgLmy
— geoff (@GeoffreyHuntley) April 15, 2021
W reakcji na tweeta, Microsoft wyrzucił go z programu, motywując to złamaniem NDA – co w sumie się wydarzyło, ale kontekst całości nie stawia firmy w najlepszym świetle. Ciekawostka: przy okazji całej sprawy dowiedzieliśmy się, że jedną z interesujących „zachęt” dla członków MVP jest 13 tysięcy dolarów rocznie do użycia w ramach chmury Azure

Całość zakończmy jednak pozytywną nutą, nieco łącząc tematy kernela Linuxa i Microsoftu.
Otóż Windows Subsystem for Linux rozwija się bardzo dynamicznie, a ostatnie poprawki umożliwiły testerom wydań Insider obsługę nie tylko shella, ale również linuxowych aplikacji desktopowych, bez żadnego dodatkowego oprogramowania. O ile historycznie możliwe już było uruchomienie serwera X w oparciu o WSL, to nowe rozwiązanie umożliwia min. akceleracje wyświetlania aplikacji za pomocą GPU. Co ciekawe, niejako w odpowiedzi w nowym Ubuntu pojawiło się natywne wsparcie dla Active Directory, a Canonical z Microsoftem przy okazji tego wydania ogłosili też wspólny komercyjny support dla SQL Servera uruchomionego na maszynach z Ubuntu.
Ach te strategiczne sojusze.

Źródła:



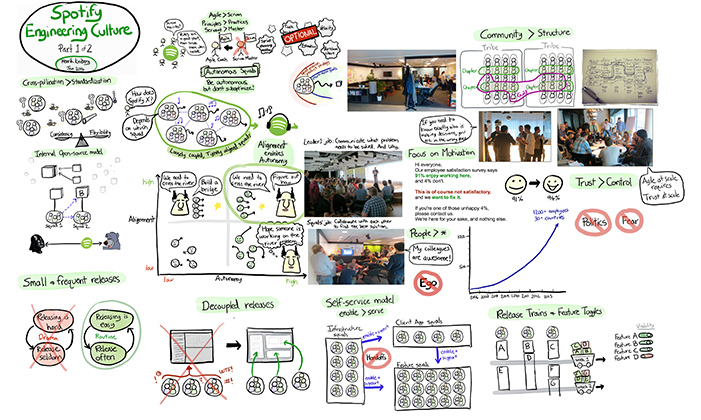
Spotify uchodzi za przykład jednej z najlepiej zarządzanych startupów technologicznych, a ich “model” organizacyjny, oparty o Składy, Plemiona, Rozdziały i Gildie dość mocno przebił się do świadomości – zwłaszcza osób poszukujących dobrego “szablonu” skalowania organizacji. „Model” został dość szeroko opisany w powszechnie chwalonej książce “Competing with Unicorns”, której to… chyba w zasadzie nie polecam. Jest bardzo ogólnikowa i o ile koncepcje w niej zawarte bardzo fajnie brzmią gdy się o nich czyta, to całość daje zaskakująco mało wskazówek praktycznych, jeżeli chcielibyście dokonać “przeszczepienia” pojawiających się w niej koncepcji do swojej firmy – chyba bardziej polecam krótkie wideo, kumulujące właściwie wszystkie bardziej interesujące informacje z książki.

Może ogólnie należy spojrzeć w innym kierunku. Okazuje się również, że swojego “modelu” nie używa już nawet sam Spotify – od czasu jego oryginalnego stworzenia poszli już do przodu i przeorganizowali sposób, w jaki pracują. W zeszłym tygodniu na ich blogu inżynierskim ukazała się bardzo ciekawa publikacja opisująca iteracje, jakie przeszła “topologia zespołów” w domenowym obszarze wyszukiwania piosenek.
Ze względu na fakt, iż jest to jedna z kluczowych funkcjonalności platformy, nie jest w stanie zająć się nią pojedynczy „squad”. W związku z tym, zarząd firmy stanął przed klasycznym dylematem: “Jak najlepiej podzielić pracę pomiędzy poszczególne zespoły”. Nie będę tutaj zdradzał za dużo, ale linkowany artykuł dotyka konsekwencji, z którymi trzeba się mierzyć jeżeli zdecydujemy podzielić się zespoły po ekspertyzie technologicznej. Publikacja prezentuje także, czego Spotify się na własnych błędach nauczył.
Ogólnie polecam, ale jeżeli z całej tej sekcji macie przeczytać tylko jeden link, niech będzie to “Spotify doesn’t use “the Spotify model” and neither should you” – jest to bardzo ważna publikacja, którą każda osoba chcąca kopiować rozwiązania od Szwedów powinna poznać.
Źródła:
Na koniec mamy dla was informacje o nowym releasie Kafki. Jest to początek nowej drogi dla tego projektu, ponieważ we wczesnym dostępie udostępniony zos
tał oczekiwany KIP-500 – usunięcie Zookeepera.

Apache ZooKeeper to komponent zapewniający dystrybucję konfiguracji oraz konsensus, używany w wielu projekt, gdzie wymagana jest wysokiej dostępność – za przykład niech posłuży np. Solr czy Spark. Jest to też niezbędny element każdego kafkowego klastra – Apache Kafka trzyma w Zookeeper metadane o topicach, borkerach, czy też consumerach. O ile jest to dość wygodne z punktu widzenia Confluenta – mogą oni używać sprawdzonego w boju, “wygrzanego” rozwiązania – o tyle dla administratorów jest to kolejny ruchomy klocek, wprowadzający spory narzut operacyjny. Dlatego też, czując na karku oddech konkurencji i chcąc ułatwić życie użytkownikom, Kafka wprowadza swoją własną wersję „konsensusu”, opartą na Raftcie. Zamiast na zewnętrznym komponencie, ma opierać się na wewnętrznym topicu o dość deskryptywnej nazwie @metadata.
Nowa wersja przynosi oczywiście sporo innych zmian, ale to właśnie wspomniany KIP-500 będzie na pewno jest głównym daniem tego wydania. Pamiętajcie jednak, że twórcy odradzają używanie rozwiązania na produkcji – jest to na razie wersja wyłącznie testowa. Wersja produkcyjna rozwiązania powinna trafić do rąk użytkowników jeszcze w tym roku.

Źródła:


