Dzisiaj to co tygryski lubią najbardziej – trzy tematy, i każdy z nich bardzo mocno technologiczny. Porozmawiamy więc o Vector API, propozycji zmian w Stream API i Hermetycznej Javie.

1. Vector API jeszcze nie wyszło z Inkubatora, a już znajduje zastosowania
Vector API jest moją ulubioną ofiarą żartów, ze względu na fakt, że pozostaje ono w wiecznej inkubacji wraz z kolejnymi wydaniami JDK, w oczekiwaniu na stabilizację API projektu Valhalla. Dla wielu projektów czekanie to jest wyjątkowo nieznośne, ponieważ Vector API przynieść ma umożliwić świadome korzystanie z SIMD, będącego skrótem od Single Instruction, Multiple Data (pojedyncza instrukcja, wiele danych). Jako, że moja mama jest nauczycielką, moją ulubioną analogią jest pedagog, który musi zaznaczyć ten sam test dla całej klasy. SIMD to oznaczanie wszystkich testów w tym samym czasie dla tego samego pytania, zamiast oznaczania każdego testu jeden po drugim, co znacznie przyspiesza proces oznaczania.

Dlatego też niektóre projekty dreptają nóżkami szybciej niż inne. Kojarzycie Lucene? Nawet jeśli nie, to na pewno na waszym radarze pojawiły się kiedyś projekty na niej oparte – Apache Solr i ElasticSearch. Lucene to bowiem napisany w Javie silnik wyszukiwarki, więc projekt, dla którego zmiany przynoszone przez Vector API są niezwykle łakomym kąskiem.
Jak opisano w publikacji Accelerating vector search with SIMD instructions, opublikowanej na blogu Elastica, Lucene osiągnęła właśnie znaczący postęp w zakresie wydajności Vector API. Operacja wyszukiwania wektorowego, kluczowa dla znajdowania podobieństwa między dwoma wektorami, tradycyjnie wykorzystywała implementacje skalarne – czyli w oparciu o działania matematyczne, które są wykonywane na pojedynczych liczbach, takie jak dodawanie, odejmowanie, mnożenie i dzielenie. Już pewnie widzicie gdzie to wszystko prowadzi – adopcja Vector API umożliwiła wykorzystanie operacji SIMD, świetnie nadających się do działań na wektorach. Do tej pory kompilator C2 już wprawdzie samodzielnie próbował optymalizować poszczególne fragmenty kodu, ale dopiero teraz programista może sam wskazać miejsca do optymalizacji. Efektem jest znaczna poprawa wydajności, odnotowana w testach porównawczych wyszukiwania wektorowego. Nazwa Vector API zobowiązuje.
Przyjęcie Vector API przez Lucene, pomimo jego inkubacyjnego statusu, oznacza kompromis między wykorzystaniem potencjalnych korzyści z świeżutkiego API, a kosztami utrzymania zależności na nieostatecznym projekcie, który może jeszcze ulec zmianie. Mimo to, Vector API przynosi na tyle dobre efekty, że zdecydowano się na utrzymywanie dwóch wersji projektu – jednej opartej o starą implementację i drugą wspartą o Vector API. Zmiany te zostaną uwzględnione już w Elasticsearch 8.9.0, a tempo to jeszcze bardziej podkreśla jak bardzo zależy twórcom na ich wprowadzeniu. Elastic też jest teraz chyba pierwszym znanym projektem, który zdecydował się na użycie inkubowanego API w swojej wersji produkcyjnej.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Jak wygląda rozwinięcie Streams API zaproponowane przez twórcę Akki?
Co się stanie kiedy były Tech Lead Akki, Viktor Klang, zaproponuje zmiany w Stream API? Wygląda na to, że dostajemy bardzo przemyślaną propozycje kierunku, w którym chyba najlepiej zaadoptowana w ostatniej dekadzie nowość w języku może być rozwijana.
Chociaż istniejący interfejs Stream API oferuje już bogaty zestaw operacji procesujących (jak .map, .filter ), istniała potrzeba rozszerzenia go i takie jak fixedWindow(2) czy scan((sum, next) -> sum + next). Propozycja Viktora wynika z powtarzających się próśb o dodanie takich dodatkowych operacji do Stream API w Javie 8, których nie można było spełnić, ponieważ ich użycie było zbyt wąskie, aby umieścić je w podstawowym Stream API. Na ten moment nie istnieje jednak opcja, żeby ktoś samodzielnie stworzył sobie własną operacje procesującą, jak to ma miejsce w przypadku interfejsu Stream::collect, w związku z czym czasem okazuje się, że osiągnięcie niektórych efektów jest zaskakująco trudne..

Nowy interfejs Stream::gather służyłby do tworzenia własnych operacja pośrednia, zdolna do obsługi wielu ich rodzaju. Viktor przeprowadził bowiem w swoim dokumencie Gathering the streams wnikliwą klasyfikacje różnego rodzaju przypadków użycia nowego API, opisujących różne rodzaje operacji strumieniowych, takich jak operacje pośrednie, operacje przyrostowe, operacje stanowe, bezstanowe… całość naprawdę dobrze opisuje wspomniany już oryginalny dokument. Gatherer, bo tak nazwany został nowy interfejs, w swojej budowie bardzo przypomina dobrze znanego Collectora, na którym zresztą został oparty.
/** @param <T> the element type
* @param <A> the (mutable) intermediate accumulation type
* @param <R> the (probably immutable) final accumulation type
*/
interface Gatherer<T,A,R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
}
Gatherer został zaprojektowany, aby zapewnić możliwość kompozycji i reużywalności poszczególnych stworzonych z jego pomocą komponentów. Jako przykład może posłużyć implementacja znanego map na wspólnej abstrakcji:
public final static <T,R> Gatherer<T, ?, R> map(Function<? super T, ? extends R> mapper) {
return Gatherer.of(
() -> (Void)null,
(nothing, element, downstream) ->
downstream.flush(mapper.apply(element)),
(l,r) -> l,
(nothing, downstream) -> {}
);
}
Polecam zapoznać się nie tylko z proposalem, ale również komentarzami, które wywołał w wątku mailowym. Ogólnie reakcje są dość entuzjastyczne, choć pojawiają się też zarzuty mówiące o pewnym skomplikowaniu propozycji. Wygląda jednak na to, że któraś z przyszłych iteracji ma szanse trafić do JDK, co powinno pozytywnie wpłynąć na możliwość rozszerzania Stream API.
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!
3. Google chce zaproponować nowy sposób dystrybucji aplikacji Java
Ostatnimi tygodniami społeczność Redditowa próbowała dokonać buntu przed wprowadzeniem opłat za użycie API, przez co wiele społeczności pozostawało na długi czas zamkniętymi. Zabrzmi nieco coehlhowsko, ale w takich momentach (kiedy go nie ma) uświadomić sobie można, jak przydatnym narzędziem jest Reddit. O ile bowiem śledzenie nowości w miarę na bieżąco bywa czasochłonne, ale jest raczej dość proste, o tyle społeczność portalu przynosi niektórym tematom znacznie szerszy kontekst, a dodatkowo potrafi wyciągnąć na wierzch tematy, które w momencie publikacji przeszły pod radarem (przynajmniej pod moim). Tak wygląda sprawa z Hermetic Java, nowym podejściem do dystrybucji aplikacji zaprezentowanym przez Jiangli Zhou z Google jeszcze w lutym. Dzięki Redditowi dostałem jednak od losu drugą szansę i możecie zapoznać się z tą naprawdę interesującą koncepcją.
Na podstawie prezentacji z proposalem i wątku mailowego wynika, że Hermetic Java jest rozwiązaniem służącym do tworzenia samodzielnych i wysokowydajnych obrazów wykonywalnych Java. Jego głównym celem jest rozwiązanie problemów związanych z pakowaniem i wdrażaniem aplikacji Java, a zwłaszcza ich późniejszej dystrybucji.
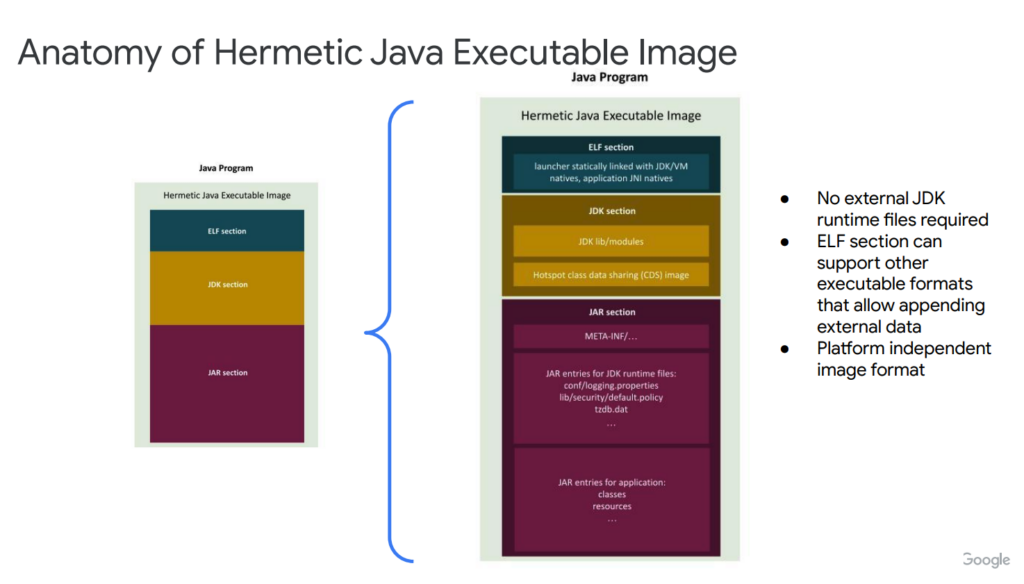
Hermetic Java to bowiem narzędzie do tworzenia samodzielnych plików wykonywalnych aplikacji JVM-owych. Wprowadza koncept obrazu wykonywalnego, który łączy instrukcje uruchamiające, JDK runtime i JAR. Obraz sam ten składa się z sekcji ELF (będącego Java Launcherem), sekcji JDK dla modułów i archiwum Class Data Sharing (CDS) oraz sekcji JAR dla aplikacji i zasobów. Dodatkowo umożliwia dynamiczne ładowanie zewnętrznych klas w razie potrzeby, ale też wspierać kod ahead-of-time. Propozycja ma inkorporować ostatnie gorące nowości w świecie JVM, inspirując się takimi inicjatywami jak GraalVM, Project Leyden, AWS Lambda SnapStart i Checkpoint-Restore in Userspace (CRaC).

Patrząc na zalety, Hermetic Java eliminuje potrzebę posiadania zewnętrznych plików środowiska uruchomieniowego JDK i nie wymaga określania konkretnej wersji JDK do wdrożenia. Dzięki temu obraz ten jest kompatybilny z różnymi środowiskami i upraszcza wdrażanie aplikacji. Tworzeniem obrazów Hermetic Java zajmować się ma singlejar, czyli narzędzie już w tej chwili używane w ramach build toola Bazel. Format obrazu jest niezależny od platformy i obsługuje zarówno linkowanie dynamiczne, jak i statyczne.
Na powierzchni Hermetic Java i GraalVM mogą wyglądać podobnie, ale nie dajcie się zwieść pozorom. Hermetic Java i GraalVM to dwa różne podejścia do kompilowania i pakowania aplikacji Java do wdrożenia. GraalVM wykorzystuje narzędzie native-image do kompilowania aplikacji AoT i opiera się na SubstratVM, alternatywnej maszynie wirtualnej. Dodatkowo, GraalVM bazuje na założeniu „zamkniętego świata” (braku możliwości dostarczenia dodatkowych klas z ClassPath), co pozwala mu na zaawansowane optymalizacje. Z drugiej strony, Hermetic Java koncentruje się na tworzeniu samodzielnego statycznego obrazu, który sam w sobie posiada wszystkie niezbędne elementy do uruchomienia aplikacji. Takie podejście eliminuje potrzebę stosowania zewnętrznego środowiska uruchomieniowego, eliminuje problemy związane z wersją JDK i może działać na różnych platformach. W przeciwieństwie do GraalVM, Hermetic Java zachowuje kompatybilność z OpenJDK i Hotspot VM, umożliwiając integrację z istniejącymi i przyszłymi funkcjami tych środowisk. Bardziej niż do obrazów GraalVM porównałbym je więc do mixu UberJara z obrazem Dockerowym.
Czekam w związku z tym na obiecanego JEP-a – zaprezentowane rozwiązanie może być interesującym rozwiązaniem dla projektów, które nie są w stanie (lub nie mają potrzeby) przejść na GraalVM.
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


