Today what tigers do best – three topics, and each of them very strongly technical. So we’ll talk about the Vector API, the proposed changes to the Stream API, and Hermetic Java.

1. Vector API gains traction even before the official launch from Incubator
The Vector API is my favorite victim of jokes, due to the fact that it remains in perpetual incubation with successive JDK releases while waiting for the Valhalla project’s API to stabilize. Many projects are eager for it because it’s meant to enable SIMD use, which stands for Single Instruction, Multiple Data. As my mother is a teacher, my favorite analogy is an educator who has to mark the same test for the entire class. SIMD is marking all the tests at the same time for the same question, instead of marking each test one by one, which speeds up the marking process considerably.

That’s why some projects twitch their feet faster than others. Are you familiar with Lucene? Even if not, projects based on it – Apache Solr and ElasticSearch – have certainly appeared on your radar in the past. After all, Apache Lucene is a Java-written search engine, so a project for which the changes brought by the Vector API are immediately useful.
As described in Accelerating vector search with SIMD instructions, published on the Elastic blog, Lucene has just made significant progress thanks to Vector API. The vector search operation, crucial for finding similarity between two vectors, has traditionally used scalar implementations – that is, based on mathematical operations that are performed on single numbers, such as addition, subtraction, multiplication, and division. By now you can probably see where all this is leading – the adoption of the Vector API has enabled the use of SIMD operations, great for vector operations. Up to now, the C2 compiler has already attempted to optimize individual code fragments on its own, but only now can the programmer point out places for optimization himself. The result is a significant improvement in performance, noted in comparative tests of vector search. The name Vector API obliges.
Lucene’s adoption of the Vector API, despite its incubation status, means a trade-off between taking advantage of the potential benefits of a fresh API and the cost of maintaining dependencies with a non-final design that may yet change. Nonetheless, the Vector API is performing well enough that it was decided to maintain two versions of the project – one based on the old implementation and one supported by the Vector API. These changes will already be included in Elasticsearch 8.9.0, and this pace further shows how much the developers are excited. Elastic is now perhaps the first widely-known project which decided to use the incubated API in its production app.
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!



2. How does the Streams API improvements proposed by the Akka Tech Lead look like?
What happens when Viktor Klang, the ex-tech head at Akka, suggests updates to the Stream API? It seems we’re receiving a well-considered idea to make the most popular new language feature of the past ten years even better.
Although the existing Stream API already offers a rich set of intermediate operations (such as .map, .filter ), sometimes there is a need to extend the list with more specialized ones like fixedWindow(2) or scan((sum, next) -> sum + next). Viktor’s proposal stems from repeated requests to add such additional operations to the Stream API in Java 8, which could be helpful for some people, but their use is too narrow to include in the basic Stream API without polluting it. What’s more, there is currently no easy option for someone to create their own processor operations, as is the case with the Stream::collect interface. As a result, it sometimes proves surprisingly difficult to achieve some results.

The new Stream::gather interface would be used to create its own intermediate operation, capable of handling many types of them. In fact, Viktor conducted in his Gathering the streams a thorough classification of different kinds of use cases for the new API, describing possible stream operations, such as indirect operations, incremental operations, stateful operations, stateless operations…. simply check original document. Gatherer, as this is the name of the new interface, in its design is very reminiscent of the well-known Collector, on which, by the way, it was based.
/** @param <T> the element type
* @param <A> the (mutable) intermediate accumulation type
* @param <R> the (probably immutable) final accumulation type
*/
interface Gatherer<T,A,R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
}
Gatherer is designed to provide composability and reusability of individual components created with its help. As an example, the implementation of a well-known map on this common abstraction:
public final static <T,R> Gatherer<T, ?, R> map(Function<? super T, ? extends R> mapper) {
return Gatherer.of(
() -> (Void)null,
(nothing, element, downstream) ->
downstream.flush(mapper.apply(element)),
(l,r) -> l,
(nothing, downstream) -> {}
);
}
I recommend reading not only the proposal, but also the comments it elicited in the email thread. In general, reactions are quite enthusiastic, although there are also accusations that the proposal is somewhat complicated. However, it looks like one of the future iterations is likely to make its way into the JDK, which should have a positive impact on the extensibility and versality of the Stream API.
Discover more IT content selected for you
In Vived, you will find articles handpicked by devs.
Download the app and read the good stuff!
3. Google wants to offer a new way to distribute Java applications
In recent weeks, the Reddit community has been trying to stage a revolt against the introduction of API usage fees, leaving many communities closed for long periods of time. It’s going to sound a bit Coelho-like, but it’s at times like this (when it’s gone) that one realizes what a useful tool Reddit is. After all, while it can be time-consuming to keep up to date with the news, it is rather straightforward. However, the portal’s community brings a much broader context to some topics, plus it can pull to the surface ones that went under the radar at the time of publication (at least under mine). Such is the case with Hermetic Java, a new approach to application distribution presented by Jiangli Zhou of Google back in February. Thanks to Reddit, however, I was given a second chance by fate, and you can familiarize yourself with this really interesting concept.
Based on a proposal presentation and email thread, it appears that Hermetic Java is a solution for creating standalone and high-performance Java executable images. Its main purpose is to solve problems related to packaging and deployment of Java applications, especially their subsequent distribution.
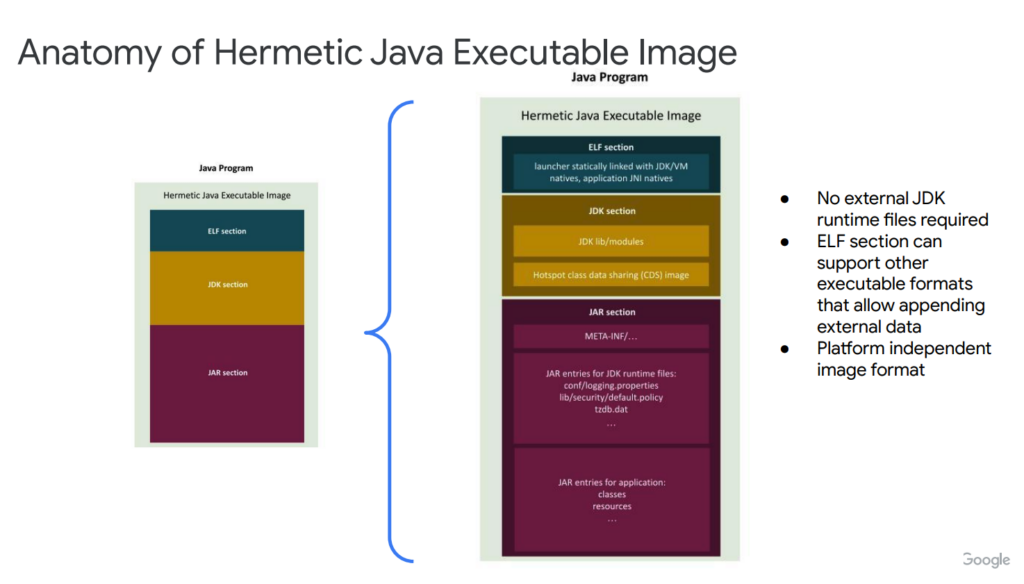
This is because Hermetic Java is a tool for creating standalone executable files for JVM applications. It introduces the concept of an executable image that combines launcher instructions, JDK runtime and JAR. The image itself consists of an ELF section (which is the Java Launcher), a JDK section for modules and a Class Data Sharing (CDS) archive, and a JAR section for applications and resources. In addition, it allows for dynamic loading of external classes when needed, while also supporting ahead-of-time compiled code. The proposal is aware of the latest trending topics in the JVM community. It draws inspiration from projects like GraalVM, Project Leyden, AWS Lambda SnapStart, or CRaC.

Looking at the advantages, Hermetic Java eliminates the need for external JDK runtime environment files and does not require specifying a specific JDK version for deployment. This makes the image compatible with different environments and simplifies application deployment. The creation of Hermetic Java images is to be handled by singlejar, a tool already in use within the Bazel ecosystem. The image format is platform-independent and supports both dynamic and static linking.
On the surface, Hermetic Java and GraalVM may look similar, but don’t be fooled by appearances. Hermetic Java and GraalVM are two different approaches to compiling and packaging Java applications. GraalVM uses the native-image tool to compile applications Ahead-of-Time and relies on SubstratVM, an alternative virtual machine. In addition, GraalVM is based on the assumption of a “closed world” (the inability to provide additional classes from Classpath), which allows it to make advanced optimizations. Hermetic Java, on the other hand, focuses on creating a standalone static image, which itself has all the necessary elements to run an application. This approach eliminates the need for an external runtime environment, eliminates JDK version issues, and can run on different platforms. Unlike GraalVM, Hermetic Java maintains compatibility with OpenJDK and Hotspot VM, allowing integration with existing and future features of these environments. So more than to GraalVM images, I would compare it to a mix of UberJar and Docker images.
In this regard, I am waiting for the promised JEP – the presented solution may be an interesting solution for projects that are not able (or do not have the need) to switch to GraalVM.
Discover more great content!
- Save time and effort
- Read handpicked articles
- Free yourself from spam

