Końcówka roku zbliża się wielkimi krokami. Czas rodzinnego ciepła, choinki, łamania się opłatkiem oraz… urlopów. Dlatego z tygodnia na tydzień widać, że “dużych wydarzeń” jest coraz mniej (przynajmniej poza światkiem javowym – wpiszcie log4j w Google i miłej zabawy, do zobaczenia we wtorek 🙈). Mimo to, mamy dzisiaj dla Was dwa interesujące ogłoszenia.

1. GitHub wprowadza precyzyjną nawigację po kodzie ✌️
GitHub jest firmą rozwijającą się niezwykle dynamicznie – myślę, że jeśli bym się postarał, to w każdej z naszych edycji zmieściłbym jakąś nowinkę od nich. Oczywiście, nie chodzi o to żebyśmy się stali GitHub Weekly (aczkolwiek prowadziłem kiedyś podobną serię, choć działającą na nieco innych zasadach 😉). Czasem jednak niektóre ogłoszenia są na tyle duże, że smutno by się było nie podzielić.
GitHub wprowadził bowiem zmiany związane z nawigacją po kodzie źródłowym. Takowa funkcjonalność już pewien czas gościła w ichniejszej przeglądarce kodu źródłowego, ale od zeszłego tygodnia można używać jej również przy przeglądaniu Pull Request. Zdecydowanie wolę ściągnięcie całego kodu zmiany i przeglądanie jej w jakimś pełnym edytorze, ale taka możliwość szybkiego podglądu w wielu sytuacjach będzie z pewnością przydatna.
Drugą zmianą wprowadzoną przez GitHub jest tak zwana “precyzyjna nawigacja do kodu pythonoweg”. Do tej pory wszystkie podpowiedzi w edytorze generowane były nie za pomocą realnej analizy kodu, a raczej poprzez robienie wyszukiwanie wystąpień w API. Teraz cały mechanizm ma być w wypadku Pythona znacznie sprytniejszy i być w stanie przewidzieć, która wersją została tutaj użyta.
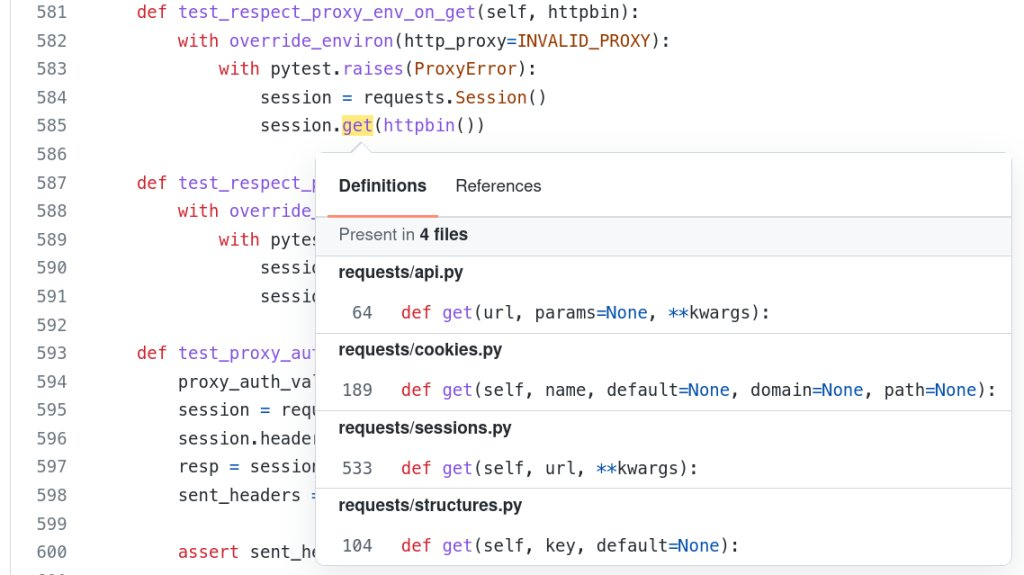
Pewnie jednak nie poświęciłbym temu ogłoszeniu miejsca w naszym przeglądzie, gdyby nie towarzysząca mu publikacja. Żeby osiągnąć rzeczoną precyzję, GitHub stworzył bowiem stack graphs – narzędzie, która zapewnia tworzenie okrojonego odpowiednika drzewa syntaktycznego dla dowolnego języka, z jednej strony zapewniając rozpoznawania nazw metod, zmiennych czy klas. To, co szczególnie interesujące to fakt, że stack graph stanowią abstrakcje nad gramatyką poszczególnych języków – mogą więc być użyte z dowolnym językiem. Generują bowiem po prostu graf powiązań między poszczególnymi metodami, dzięki czemu GitHubowy edytor wie, które warianty naprawdę zostały w danym pliku użyte.
Jeżeli kiedykolwiek interesowała Was narzędziówka do tworzenia narzędzi developerskich (a wiem, że mamy takowych smakoszy wśród czytelników), zdecydowanie powinniście przyglądnąć się stack graphs. Zostały przystępnie opisane przez GitHuba w poście, a cechują się pewnymi kreatywnymi rozwiązaniami technicznymi.
Źródła
- Precise code navigation for Python, and code navigation in pull requests
- github/stack-graphs: Rust implementation of stack graphs
- Introducing stack graphs
Odkryj więcej treści IT dopasowanych do Ciebie
W aplikacji Vived znajdziesz artykuły moderowane przez developerów.
Zainstaluj teraz i czytaj tylko dobre teksty!
Zainstaluj teraz i czytaj tylko dobre teksty!



2. Nowa Ostatnia Granica – Kubernetes 1.23 zawitał 🐳

stack graphs to ciekawy, ale równocześnie mocno niszowy projekt dla bardzo specyficznego odbiorcy. Z zeszłotygodniowych premier z pewnością dużo mocniej większość z Was zaafektuje nowa wersja Kubernetesa, o dość znamiennej nazwie “The Next Frontier”. Co przynosi, żeby zasłużyć na tak buńczuczne miano?
To co rzuca się w oczy to fakt, że Container Runtime Interface (CRI) nareszcie staje się rozwiązaniem domyślnym. Nasi wierni czytelnicy zdają sobie sprawę, że Kubernetes od pewnego czasu pozbywa się zależności na Dockerze, który ze wszystkimi swoimi rozwiązaniami stworzonymi dla wygody pojedynczego użytkownika wprowadza spory narzut w przypadku użycia w klastrze. Właśnie w celu zastąpienia pociesznego wielorybka powstał kompatybilny z nim CRI. Rozwiązanie można było już testować w poprzedniej edycji, a teraz twórcy są już pewni go na tyle, żeby uczynić z niego domyślne środowisko uruchomieniowe dla kontenerów.
Kolejna duża nowość w nowym Kubernetes to równoległe wsparcie IPv4 i IPv6 dla pojedynczych serwisów. Jest to bardzo istotny dodatek z punktu widzenia procesów migracji z IPv4 do IPv6, co ze względu na popularyzację tego drugiego standardu według twórców Kubernetesa staje się coraz częstsze. Teraz w okresie przejściowym będzie można stopniowo dodawać nowe adresy IPv6 poszczególnym serwisom posiadającym już adresy IPv4 bez żadnego downtime. Pozwala przetrwać to etap przejściowy, gdy cały klaster jeszcze nie zmigrował się na IPv6 i potrzebne jest równolegle posiadanie dwóch adresów. Więcej szczegółów znajdziecie w poście blogowym oraz oryginalnym design docu (szczególnie polecam ten drugi – jest dłuższy, ale pomógł mi zrozumieć motywacje stojące za całym procesem)
Aż mnie ciekawi co nie dla pełnoletnich można dostać wyszukując „kubernetes ipv4/ipv6 dual-stack”
Oczywiście, nowy Kubernetes to sporo więcej, dlatego zapraszam do lektury pełnych Release Notes.
Źródła
Odkryj więcej świetnych treści!
- Rozsądna ilość treści
- Tylko wysoka jakość
- Pełne dopasowanie do Twoich potrzeb!


